lightspeedGPT is a Python script that utilizes a multithreading approach to overcome the token limitations of the OpenAI API.
Large input data is split into manageable chunks which are sent to the API simultaneously, with responses collected and reassembled. Exponential backoff with jitter is used in case rate limit issues arise.
Features:
- Remove constraints on input size allowing huge datasets, books, articles, etc. to be processed
- Multithreading enables parallel processing of input chunks for fast results
- Supports the latest GPT-4 and GPT-3.5 models
- Free to use with your own OpenAI API key
Usages:
To use LightspeedGPT, you will need Python 3.6 or above, an OpenAI API key, and basic familiarity with command-line interfaces. Simply clone the GitHub repository, install the necessary packages, and set your OpenAI API key as an environment variable. With these prerequisites fulfilled, the script is ready to handle large-scale text processing tasks with incredible speed and efficiency.
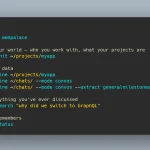
git clone https://github.com/your_username/openai-text-processor.git
cd openai-text-processor
export OPENAI_KEY=your_openai_key
python main.py -i INPUT_FILE -o OUTPUT_FILE -l LOG_FILE -m MODEL -c CHUNKSIZE -t TOKENS -v TEMPERATURE -p PROMPT
Parameters:
INPUT_FILE: The path to the input file. Required.OUTPUT_FILE: The path to the output file. Required.LOG_FILE: The path to the log file. Required.MODEL: Select the OpenAI model to use (default is ‘gpt-3.5-turbo-0301’). Alternative: gpt-4-0314. Better quality but slower and more expensive.CHUNKSIZE: The maximum number of tokens per chunk (default is 1000). This shouldn’t be too large (>4000) or OpenAI will be overloaded. A safe size is under 3000 tokens. Your prompt length also counts for the OpenAI token limit.TOKENS: The maximum tokens per API call (default is 100). shorter will be faster. but could terminate too early.TEMPERATURE: The variability (temperature) for OpenAI model (default is 0.0). 0.0 is probably best if you are going for highest accuracyPROMPT: The prompt for the OpenAI model. Required. Counts towards the 4k token limit for OpenAI API calls.
Use Cases:
- Researchers can utilize LightspeedGPT to perform Named Entity Recognition or extract information from vast datasets or books.
- Content creators can use the script to translate or summarize extensive text files, such as articles or textbooks.
- Data scientists and linguists could use the script to extract geographic entities or perform other specific analysis on large historical texts.