OmniVoice Studio is a free, open-source desktop app for local voice cloning, voice design, voice dictation, and video dubbing.
It runs on Windows, macOS, Linux, and Docker, uses local TTS and ASR engines, and does not require an OmniVoice account or cloud API key for core voice work.
Voice AI tools have split into two camps: polished cloud services (like ElevenLabs) that meter every character, and open-source command-line models that demand Python environments, manual dependency resolution, and careful VRAM budgeting.
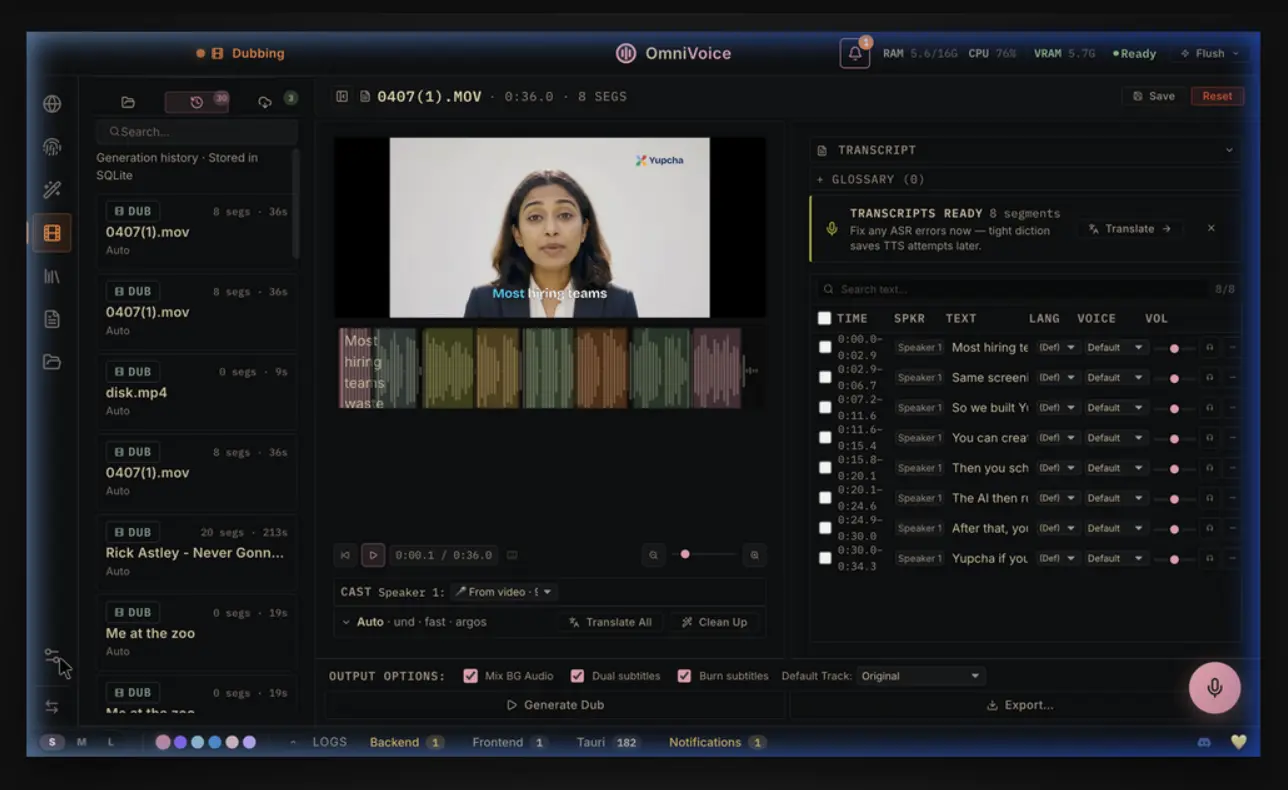
OmniVoice Studio packages 6 TTS engines and 7 speech-recognition backends inside a single desktop GUI.
The voice cloning pipeline, the video dub timeline, the batch queue, the dictation widget, and the speaker diarization module all share the same local model infrastructure.
Pick the engine, load or design a voice profile, and choose the output format. The application detects your GPU, downloads the models, switches engines, and offloads TTS from VRAM during transcription without manual configuration.
Features
- Clones a voice from a 3-second audio sample across 646 languages.
- Creates new synthetic voices with controls for gender, age, accent, pitch, speed, emotion, and dialect.
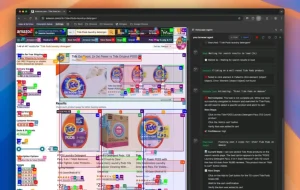
- Dubs videos from a YouTube URL or uploaded file through transcription, translation, re-voicing, and MP4 export.
- Runs a dictation widget from any app through the
⌘+⇧+Spacehotkey on supported desktop setups. - Separates vocals from background audio with Demucs, then keeps the background track in the dubbing pipeline.
- Identifies speakers with Pyannote and WhisperX when the required Hugging Face access is configured.
- Processes batch jobs with per-job progress tracking.
- Connects to Claude, Cursor, and other MCP clients through its MCP server.
- Adds invisible AudioSeal watermarking for AI provenance.
- Stores projects, generated voice profiles, exports, and history in a searchable local library.
- Auto-detects CUDA, Apple Silicon MPS, ROCm, and CPU paths.
- Offloads TTS to CPU on lower-VRAM GPUs during transcription.
- Exposes backend logs, frontend logs, and Tauri runtime logs inside the app.
- Lets advanced users add a new TTS engine through the backend registry.
OmniVoice Studio vs. ElevenLabs
OmniVoice Studio and ElevenLabs solve similar voice tasks, but they make different product decisions.
ElevenLabs is the cleaner hosted platform for polished voice generation, API access, voice agents, and a large voice library.
OmniVoice Studio is the better match when local processing, open-source access, and desktop control matter more than cloud convenience.
| OmniVoice Studio | ElevenLabs | |
|---|---|---|
| Access model | Free open-source desktop app. | Hosted web app and API platform. |
| Processing | Runs on your own machine after setup. | Runs through ElevenLabs cloud services. |
| Account requirement | No OmniVoice account for core local tasks. | Account required. |
| Pricing model | Free under AGPL-3.0. | Free tier plus paid credit plans. |
| Voice cloning | 3-second zero-shot cloning. | Instant and professional voice cloning. |
| Voice design | Controls gender, age, accent, pitch, speed, emotion, and dialect. | Voice design and a large voice library. |
| TTS languages | OmniVoice model targets 646 languages. | Eleven v3 TTS supports 74 languages. |
| Dubbing | Local dubbing from YouTube URLs or files. | Cloud dubbing across 90+ languages. |
| API access | Local app and MCP server. | REST API with Python and TypeScript SDKs. |
| Best advantage | Local privacy, open-source control, no per-character billing. | Polish, hosted reliability, API ecosystem, voice library. |
| Main drawback | Setup, model downloads, beta status, hardware limits. | Cloud dependency, credits, plan limits, uploaded media. |
How To Use It
Get Started
1. Download the desktop app from the release page. You can also use the source install when you want the newest beta fixes or your platform lacks a matching package.
2. Launch the app. The first run creates the Python environment, syncs dependencies, and downloads model weights. Plan for a large first download.
3. Open Settings and check the active system device. OmniVoice Studio can run on CUDA, Apple Silicon MPS, ROCm, or CPU. CPU mode is usable, but large TTS and dubbing jobs will take longer.
4. Add a Hugging Face token in Settings > API Keys when you plan to use diarization or gated engines. The app can store the token in its encrypted SQLite settings store and also write it to the standard Hugging Face token location for subprocess engines.
5. Open Settings > Models and install the models you need. Start with the default OmniVoice TTS engine and default WhisperX ASR engine unless you already know you need an Apple Silicon MLX path, a smaller CPU engine, or a specific ASR backend.
6. Start with a voice clone or voice design task before running a full video dub. A short test makes it easier to check reference audio quality, pacing, pronunciation, and target voice character.
7. Use a clean, consented reference voice clip. Remove background noise when possible. Speaker similarity depends heavily on the reference clip and the target language.
8. Start a dubbing project from a local file or YouTube URL. Review transcription segments before export when the video has overlapping speakers, music, or noisy room audio.
9. Export the finished project. Video dubbing targets MP4 output. Audio and subtitle workflows can include stems, SRT, VTT, and MP3 outputs depending on the project path.
10. Run the built-in self-check when setup fails. The app includes Settings > About > Run self-check, and source installs can run the diagnostic command from the project folder.
System Requirements
| Requirement | Minimum | Recommended |
|---|---|---|
| OS | Windows 10, macOS 12+, Ubuntu 20.04+ | Modern 64-bit OS |
| RAM | 8 GB | 16 GB+ |
| VRAM | 4 GB | 8 GB+ |
| Disk | 10 GB free | 20 GB+ SSD |
| Python | 3.10+ managed by uv | Python 3.11 or 3.12 |
| GPU | Optional | NVIDIA CUDA, Apple Silicon MPS, or AMD ROCm |
A CPU-only setup can run the pipeline, but large models and full video dubbing will be slower. GPUs with 8 GB VRAM or less trigger automatic TTS offloading during transcription.
TTS Engines
The default OmniVoice engine is always available. Other TTS engines are opt-in and auto-detected. Change the engine in Settings > TTS Engine or through OMNIVOICE_TTS_BACKEND.
| Engine | Languages | Cloning | Instruct | Platform notes | License |
|---|---|---|---|---|---|
| OmniVoice | 600+ | Yes | Yes | Linux CUDA/CPU, macOS MPS, Windows CUDA/CPU | Built-in |
| CosyVoice 3 | 9 plus 18 dialects | Yes | Yes | Linux CUDA/CPU, macOS MPS, Windows CUDA/CPU | Apache-2.0 |
| MLX-Audio | Multi | Varies | Varies | Apple Silicon native only | Varies |
| VoxCPM2 | 30 | Yes | Yes | Linux CUDA/CPU, macOS MPS, Windows CUDA/CPU | Apache-2.0 |
| MOSS-TTS-Nano | 20 | Yes | No | Linux CUDA/CPU, macOS CPU, Windows CUDA/CPU | Apache-2.0 |
| KittenTTS | English | No | No | CPU on Linux, macOS, and Windows | MIT |
ASR Engines
WhisperX is the default cross-platform ASR engine. Other ASR engines are opt-in and auto-detected. Change the engine in Settings > ASR Engine or through OMNIVOICE_ASR_BACKEND.
| Engine | OMNIVOICE_ASR_BACKEND | Languages | Main use |
|---|---|---|---|
| WhisperX | whisperx | Around 100 | Dubbing and subtitles with word-level timing. |
| Faster-Whisper | faster-whisper | Around 100 | Fast transcription through CTranslate2. |
| MLX Whisper | mlx-whisper | Around 100 | Apple Silicon transcription through MLX and Metal. |
| PyTorch Whisper | pytorch-whisper | Around 100 | CUDA and CPU fallback through Transformers. |
| Parakeet TDT | nemo-parakeet | English plus 25 European languages | GPU-based English transcription and automatic language detection. |
| Moonshine | moonshine | English | Edge and low-latency transcription through ONNX. |
| FunASR | funasr | 50+ | Multilingual transcription with VAD and inline diarization. |
Alternatives and Related Resources
- OmniVoice Studio Official Website
- OmniVoice Studio GitHub Repo
- OmniVoice Studio Docs
- 7 Best Free AI Voice Cloning Tools
- dots.tts: Free Open-Source Voice Cloning With 24-Language Support
- Free On-Device TTS With 31-Language Support – Supertonic v3
Pros
- Fully local core workflow.
- No OmniVoice account required.
- Multiple TTS engines.
- Desktop and Docker paths.
- Video dubbing pipeline included.
- Dictation widget included.
- AGPL commercial use permitted.
Cons
- Large first model download.
- CPU mode runs slower.
- Docker lacks built-in authentication.
- Some engines need extra access.
FAQs
Q: Does OmniVoice Studio require a sign-up?
A: Core local voice cloning, voice design, dictation, and dubbing do not require an OmniVoice account or cloud API key. Speaker diarization and some gated model downloads require a Hugging Face token and model-license acceptance.
Q: Does OmniVoice Studio run fully locally?
A: The app runs the voice workflow on your hardware after installation and model downloads. It still needs network access to download models from Hugging Face unless the required models already exist in your local cache.
Q: Can OmniVoice Studio dub YouTube videos?
A: Yes. The dubbing workflow accepts a YouTube URL or local video file, then runs transcription, translation, voice generation, mixing, and MP4 export.
Q: How does voice cloning quality compare to ElevenLabs?
A: For short clips under roughly 30 seconds, OmniVoice Studio voice cloning quality is comparable to ElevenLabs and scores higher on some benchmarks for Chinese and several other languages. Audio clips of a minute or more can show degraded rhythm and emotional consistency. ElevenLabs still leads on pre-made voice library depth and cloud API polish.
Q: Can I use this for commercial video dubbing work?
A: Yes. You can dub your own videos, dub client videos, and sell the resulting audio output. The AGPL-3.0 license explicitly permits commercial use of the audio you produce. You only need a separate commercial license if you modify the OmniVoice Studio application code and distribute that modified version as part of a closed-source product.