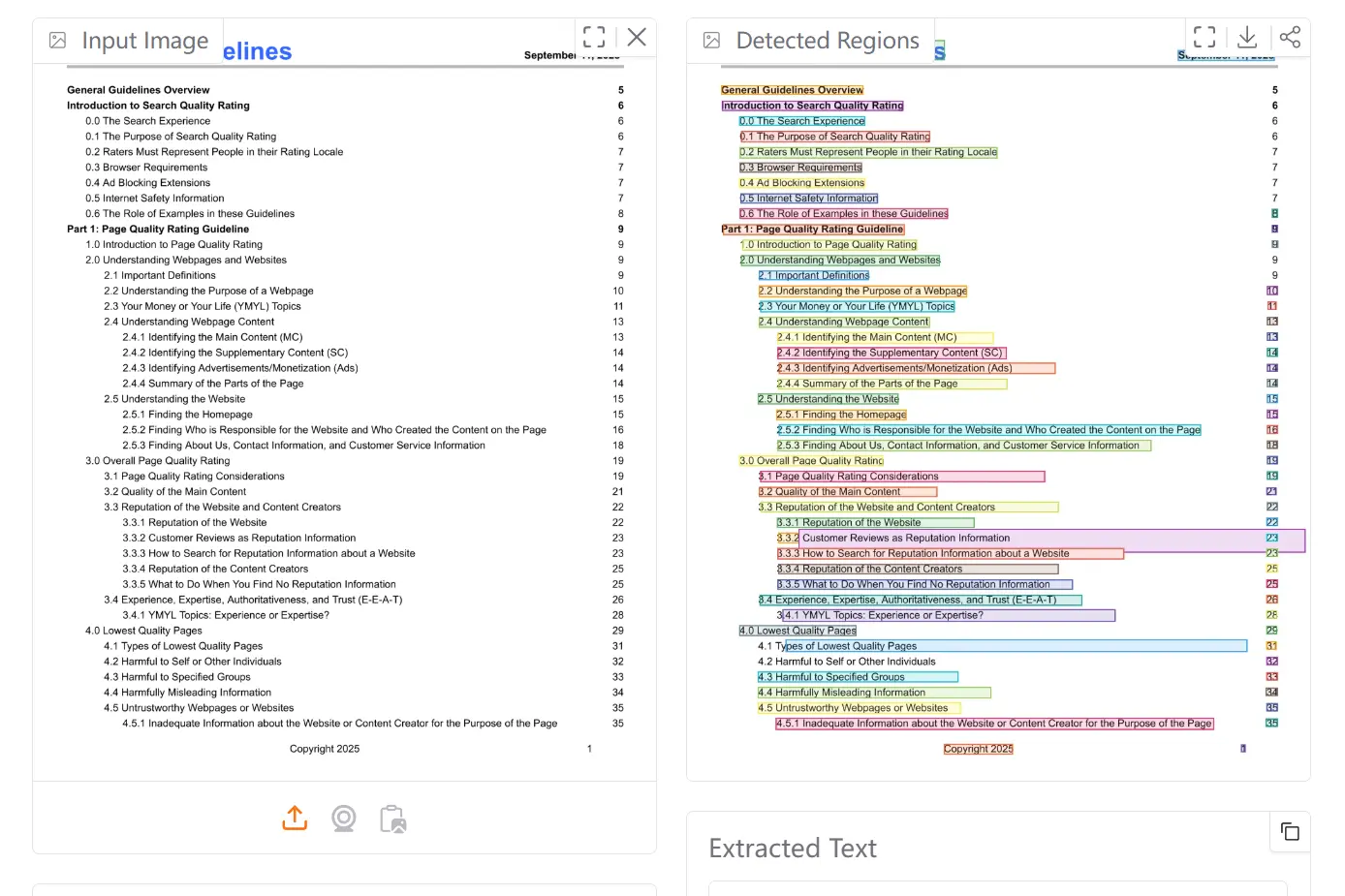
Nemotron OCR v2 is a free, open-source, ultra-fast OCR model from NVIDIA that extracts text from images of documents, signs, charts, tables, and handwritten pages.
It currently supports 6 languages (English, Chinese (Simplified and Traditional), Japanese, Korean, and Russian) and is licensed under the NVIDIA Open Model License.
This model is great for developers and teams that need OCR inside document ingestion, retrieval, RAG, or agent workflows.
It helps most when a project needs structured OCR output, multilingual support, or local deployment on NVIDIA hardware.
Features
- Detects text regions, transcribes them, and analyzes document layout and reading order in a single end-to-end pipeline.
- Comes with two variants: v2_english for English-only word-level OCR (53.8M parameters) and v2_multilingual for six-language line-level OCR (83.9M parameters).
- Processes both single images and batches with automatic multi-scale resizing.
- Accepts RGB images in PNG or JPEG format, with float32 or uint8 pixel values.
- Returns bounding box coordinates, recognized text strings, and per-region confidence scores for every detected text region.
- Supports three aggregation levels for output: word, sentence, or paragraph.
- Includes a detector-only inference mode that skips recognition and uses ~37% less GPU memory.
- Includes a skip-relational mode that drops reading-order analysis and uses ~35% less GPU memory.
- Runs on NVIDIA Ampere, Hopper, Lovelace, and Blackwell GPU architectures.
Use Cases
- Feed scanned contracts, invoices, or forms into a RAG pipeline by extracting structured text and bounding boxes from each page.
- Process multilingual product packaging, signage, or restaurant menus that mix Japanese, Chinese, Korean, Russian, and English text on a single image.
- Convert charts, infographics, and tables in business reports into text for downstream search indexing or data analysis.
- Run batch OCR across thousands of archival document scans at 34+ pages per second on a single GPU.
- Extract handwritten notes from photographed pages for digitization workflows in research or education settings.
Benchmark Results
NVIDIA published benchmark numbers on two standard OCR evaluation datasets. All scores use Normalized Edit Distance (NED), where lower numbers mean better accuracy. Speed was measured on a single A100 GPU.
OmniDocBench Results
This benchmark covers English, Chinese, and mixed-language documents across different backgrounds and text orientations.
| Model | Pages/s | EN | ZH | Mixed | Normal | Rotate90 | Rotate270 |
|---|---|---|---|---|---|---|---|
| Nemotron OCR v2 (EN) | 40.7 | 0.038 | 0.830 | 0.437 | 0.353 | 0.232 | 0.827 |
| PaddleOCR v5 (server) | 1.2 | 0.027 | 0.037 | 0.041 | 0.031 | 0.116 | 0.897 |
| OpenOCR (server) | 1.5 | 0.024 | 0.033 | 0.049 | 0.028 | 0.042 | 0.761 |
| EasyOCR | 0.4 | 0.095 | 0.117 | 0.326 | 0.110 | 0.987 | 0.979 |
| Nemotron OCR v1 | 39.3 | 0.038 | 0.876 | 0.436 | 0.482 | 0.358 | 0.871 |
Nemotron OCR v2 (multilingual) is roughly 29x faster than PaddleOCR and 87x faster than EasyOCR. PaddleOCR and OpenOCR still post lower NED scores on English and Chinese text in normal orientation, so they remain more accurate per-character in those specific categories.
Nemotron v2’s advantage shows up in speed and in handling rotated text at 90° and 270°, where it outperforms most competitors by a wide margin.
SynthDoG Results
This synthetic benchmark tests per-language accuracy across six languages.
| Language | Nemotron OCR v2 (multilingual) | PaddleOCR (specialized) | OpenOCR (server) | Nemotron OCR v1 |
|---|---|---|---|---|
| English | 0.069 | 0.096 | 0.105 | 0.078 |
| Japanese | 0.046 | 0.201 | 0.586 | 0.723 |
| Korean | 0.047 | 0.133 | 0.837 | 0.923 |
| Russian | 0.043 | 0.163 | 0.950 | 0.564 |
| Chinese (Simplified) | 0.035 | 0.054 | 0.061 | 0.784 |
| Chinese (Traditional) | 0.065 | 0.094 | 0.127 | 0.700 |
The multilingual variant dominates across every language in this benchmark. Japanese, Korean, and Russian scores are dramatically better than any competitor. The v2 multilingual model scores 0.046 on Japanese compared to PaddleOCR’s 0.201 and OpenOCR’s 0.586.
How to Use Nemotron OCR v2
Table Of Contents
Try the Free Demo
The Hugging Face Spaces demo at huggingface.co/spaces/nvidia/nemotron-ocr-v2 lets you upload an image and get OCR results without any local setup.
System Requirements
| Requirement | Details |
|---|---|
| Operating System | Linux amd64 |
| GPU | NVIDIA GPU (Ampere, Hopper, Lovelace, or Blackwell) |
| CUDA Toolkit | Must match your PyTorch CUDA version (same major version) |
| Python | 3.12 (requires >=3.12,<3.13) |
| Build Tools | GCC/G++ with C++17 support, CUDA headers, OpenMP |
| Runtime Engine | PyTorch |
Supported GPU hardware: H100 PCIe/SXM, A100 PCIe/SXM, L40S, L4, A10G, H200 NVL, B200, and RTX PRO 6000 Blackwell Server Edition.
Installation via pip
Install git-lfs first, then clone the repository:
git lfs install
git clone https://huggingface.co/nvidia/nemotron-ocr-v2
Create a Python 3.12 environment and install PyTorch for your CUDA version:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128
Install the Nemotron OCR package. The --no-build-isolation flag is required so the C++ CUDA extension compiles against your existing PyTorch:
cd nemotron-ocr
pip install --no-build-isolation -v .
Verify the installation:
python -c "from nemotron_ocr.inference.pipeline_v2 import NemotronOCRV2; print('OK')"
Installation via Docker
Confirm Docker can access your GPU:
docker run --rm --gpus all nvcr.io/nvidia/pytorch:25.09-py3 nvidia-smi
Run the example directly from the repo root:
docker compose run --rm nemotron-ocr \
bash -lc "python example.py ocr-example-input-1.png --merge-level paragraph"
This builds a container from the included Dockerfile (based on nvcr.io/nvidia/pytorch), mounts the repo at /workspace, and runs example.py. The multilingual model downloads from Hugging Face on first run. Output saves as <name>-annotated.<ext> alongside your input image.
Running Inference
The main entry point is NemotronOCRV2 from nemotron_ocr.inference.pipeline_v2. The default behavior downloads and loads the multilingual variant.
from nemotron_ocr.inference.pipeline_v2 import NemotronOCRV2
# Default: multilingual v2
ocr = NemotronOCRV2()
predictions = ocr("ocr-example-input-1.png")
for pred in predictions:
print(
f" - Text: '{pred['text']}', "
f"Confidence: {pred['confidence']:.2f}, "
f"Bbox: [left={pred['left']:.4f}, upper={pred['upper']:.4f}, "
f"right={pred['right']:.4f}, lower={pred['lower']:.4f}]"
)
Constructor Parameters
| Parameter | Values | Effect | |
|---|---|---|---|
lang=None (default) | None, "multi", "multilingual" | Loads v2 multilingual from Hugging Face Hub | |
lang="en" | "en", "english" | Loads v2 English (word-level) from Hub | |
lang="v1" | "v1", "legacy" | Loads v1 English-only model from nvidia/nemotron-ocr-v1 for backward compatibility | |
model_dir="./path" | Local directory path | Loads from a local checkpoint folder containing detector.pth, recognizer.pth, relational.pth, and charset.txt. Overrides lang when the folder is complete | |
detector_only=True | Boolean | Runs the detector only. Returns bounding boxes with no text recognition. Uses ~37% less GPU memory and runs ~20% faster | |
skip_relational=True | Boolean | Skips the relational model. Returns per-word text with no reading-order grouping. Uses ~35% less GPU memory and runs ~8% faster | |
verbose_post=True | Boolean | Enables per-phase CUDA-synced timing in the logs (profiling mode). Requires logging.basicConfig(level=logging.INFO) |
The model_dir parameter takes priority over lang. If you pass model_dir but the checkpoint folder is incomplete, loading falls back to Hub resolution using lang (which defaults to multilingual when set to None).
Inference Modes
Full pipeline (default): Detects text, recognizes it, and groups results by reading order. Each prediction returns text, confidence, left, right, upper, and lower.
Detector only (detector_only=True): Returns bounding boxes without running recognition. Each prediction returns confidence, left, right, upper, lower, and quad.
ocr_det = NemotronOCRV2(detector_only=True)
boxes = ocr_det("page.png")
Skip relational (skip_relational=True): Returns per-word text without grouping it into reading order. Call with merge_level="word" for word-level output.
ocr_fast = NemotronOCRV2(skip_relational=True)
words = ocr_fast("page.png", merge_level="word")
Profiling mode (verbose_post=True): Logs per-phase CUDA-synced timing.
import logging
logging.basicConfig(level=logging.INFO)
ocr_profile = NemotronOCRV2(verbose_post=True)Model Architecture Reference
Both variants use a three-component architecture trained end-to-end:
- Text Detector: A RegNetX-8GF convolutional backbone that localizes text regions in the image.
- Text Recognizer: A pre-norm Transformer-based sequence model that transcribes detected regions.
- Relational Model: A multi-layer global relational module that predicts reading order, logical groupings, and layout relationships across detected text elements.
Recognizer Spec Comparison
| Spec | v2_english | v2_multilingual |
|---|---|---|
| Transformer layers | 3 | 6 |
Hidden dimension (d_model) | 256 | 512 |
FFN width (dim_feedforward) | 1024 | 2048 |
| Attention heads | 8 | 8 |
| Max sequence length | 32 | 128 |
| Character set size | 855 | 14,244 |
Total Parameter Counts
| Component | v2_english | v2_multilingual |
|---|---|---|
| Detector | 45,445,259 | 45,445,259 |
| Recognizer | 6,130,657 | 36,119,598 |
| Relational model | 2,255,419 | 2,288,187 |
| Total | 53,831,335 | 83,853,044 |
Input and Output Specification
Input:
| Property | Value |
|---|---|
| Format | RGB image (PNG or JPEG), float32 or uint8 |
| Dimensions | 3 × H × W (single) or B × 3 × H × W (batch) |
| Pixel range | [0, 1] for float32 or [0, 255] for uint8 (auto-converted) |
| Aggregation levels | word, sentence, or paragraph |
Output:
| Property | Value |
|---|---|
| Bounding boxes | 1D list of coordinate tuples (floats) |
| Recognized text | 1D list of strings |
| Confidence scores | 1D list of floats |
Training Data
The model was trained on approximately 12 million images: roughly 680,000 real-world images (scene text, charts, tables, handwritten pages, multilingual documents) and over 11 million synthetic rendered pages across six languages. Synthetic data includes historical document crops with degradation effects for archaic character support.
Pros
- 20x+ faster than PaddleOCR and OpenOCR on the same hardware.
- The multilingual variant handles six languages with a single model load.
- Detector-only and skip-relational modes let you trade features for speed and memory savings on constrained hardware.
- The relational model preserves reading order and document structure.
Cons
- Runs only on NVIDIA GPUs with CUDA.
- Linux-only. No Windows or macOS support.
- Requires Python, CUDA, and local build tooling.
Related Resources
- Hugging Face Model Page: Download model weights, read the full model card, and access both
v2_englishandv2_multilingualcheckpoints. - NVIDIA Open Model License Agreement: Check commercial-use terms and redistribution rules before production rollout.
- NVIDIA Build Platform: Access the model via NVIDIA’s hosted API endpoint.
- OmniDocBench: Review the benchmark dataset used to evaluate Nemotron OCR v2 against other models.
- SynthDoG: Explore the synthetic document generator used for the multilingual benchmark evaluation.
- PyTorch Installation Guide: Match your PyTorch install to your CUDA toolkit version before installing Nemotron OCR.