Google AI has unveiled Mirasol3B, a groundbreaking multimodal autoregressive model designed to learn from audio, video, and text data. This model addresses the complex challenge of processing inputs from heterogeneous modalities, which often differ significantly in synchronization and data volume. Traditional multimodal models struggle to integrate these varied inputs effectively, particularly for longer videos, due to the disproportionate volume of audio and video data compared to text.
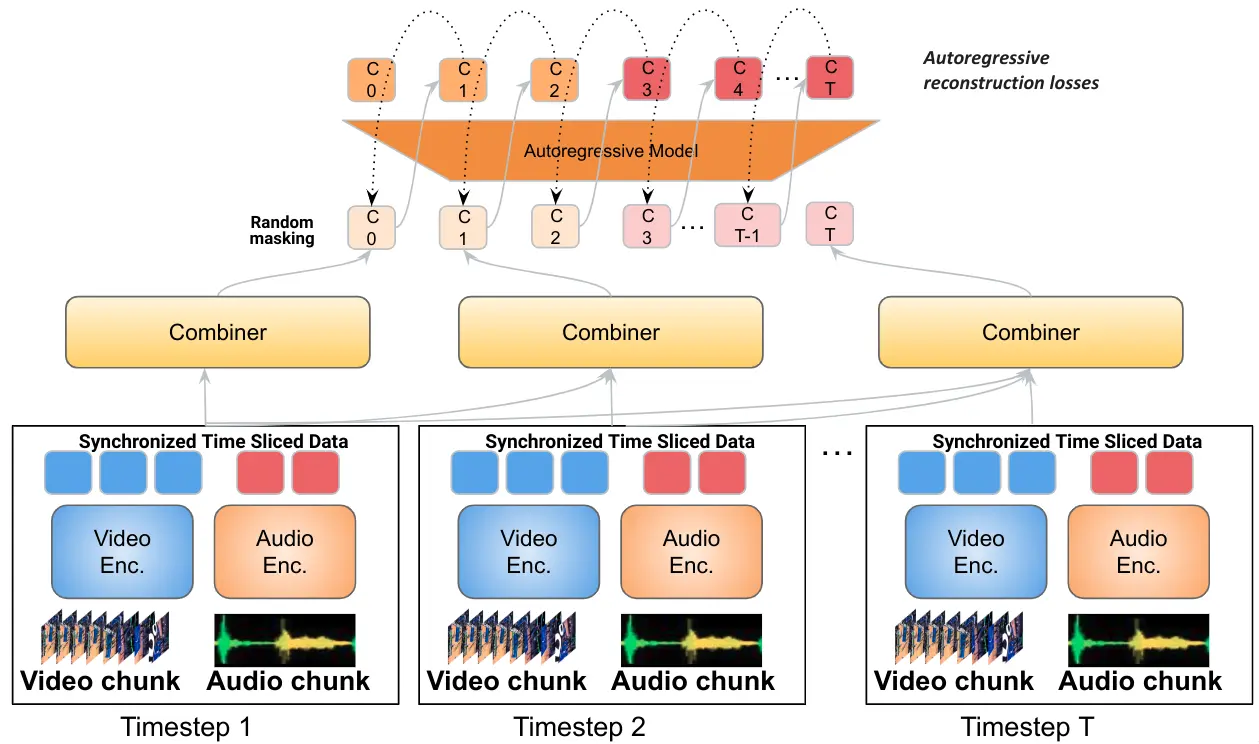
Mirasol3B innovates by decoupling multimodal modeling into distinct autoregressive models, each tailored to the specific characteristics of the modalities it handles. The architecture comprises an autoregressive component for time-synchronized modalities (audio and video) and another for sequential but not necessarily time-aligned modalities (like text). This separation allows for more efficient and specialized processing of each data type. For instance, time-aligned modalities like audio and video are partitioned temporally to facilitate joint feature learning.

A unique aspect of Mirasol3B is its ability to handle significantly longer videos (ranging from 128 to 512 frames) with ease, a feat not achievable by previous models. This capacity stems from its design, which assigns more parameters to audio-video inputs compared to earlier works, enabling it to process extensive data more effectively.
At its core, Mirasol3B utilizes a module known as the ‘Combiner’ for joint feature learning. This module aligns video and audio signals temporally, processes them to extract relevant information, and then reduces the dimensionality of the joint inputs. The Combiner can either function as a causal Transformer, processing inputs in a time-ordered manner, or have a learnable memory for more efficient data handling.
The introduction of Mirasol3B marks a significant advancement in the field of AI, particularly in the realm of multimodal learning. Its innovative architecture and efficient processing capabilities set a new benchmark for state-of-the-art performance in video question answering and audio-video-text benchmarks, eclipsing previous models in both compactness and effectiveness.