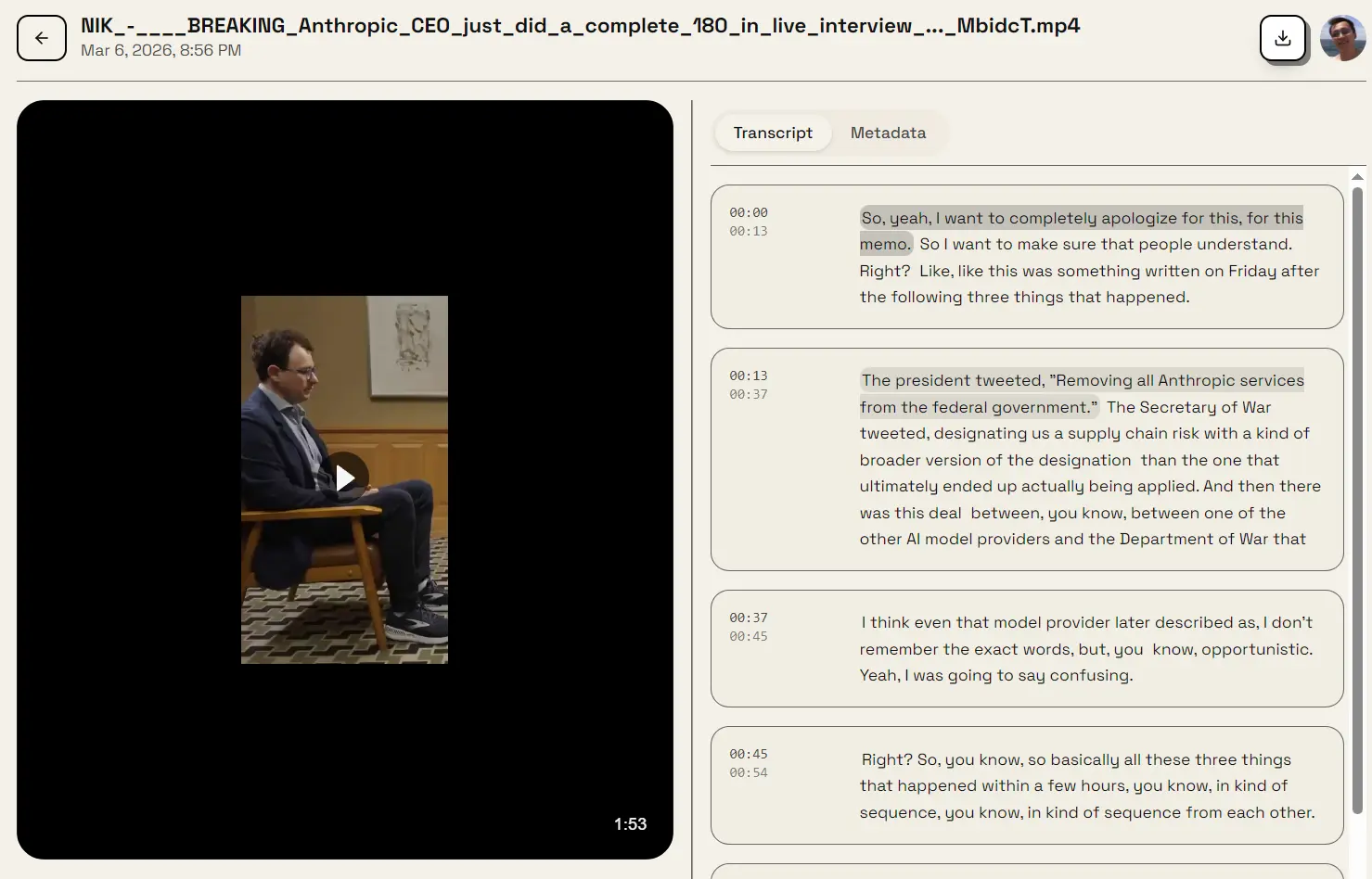
VideoToText is a freemium, AI-powered video transcription tool that converts spoken audio from video files into structured, time-stamped text. It uses enterprise-grade speech recognition to process interviews, lectures, webinars, and meeting recordings.
The tool supports 55+ languages and processes a 60-minute video in 2 to 3 minutes. This speed comes from GPU-accelerated processing on the backend. You get a full transcript with speaker identification and timestamps, ready to export in TXT, SRT, VTT, DOCX, or CSV format.
Features
- Multi-format video upload: Accepts MP4, MOV, MKV, WebM, AVI, and audio files including MP3, WAV, and M4A.
- 55+ language support: Auto-detects the spoken language and transcribes with native-level accuracy.
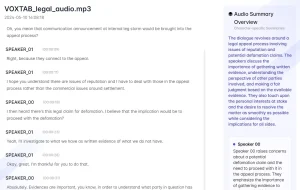
- Speaker identification: Detects multiple speakers in the audio and labels them separately in the transcript.
- Timestamping: Generates word-level or segment-level timestamps throughout the transcript.
- Multiple export formats: Downloads transcripts as TXT, SRT, VTT, DOCX, or CSV files.
- File size support: Accepts uploads up to 5 GB per file on both free and paid plans.
Use Cases
- Content Repurposing for Creators: YouTubers and podcasters can turn episode audio into show notes, blog posts, or social media snippets.
- Academic Research and Interview Analysis: Researchers transcribe interviews, focus groups, or lectures. The timestamps allow for accurate citations, and the text makes it easy to search for themes or specific quotes across multiple recordings.
- Business Documentation and Compliance: Teams convert meeting recordings, training sessions, and webinars into searchable documents. This builds a knowledge base from video content and helps document decisions.
- Accessibility and Captioning: Organizations generate accurate captions for video content to comply with ADA and WCAG standards. The exported SRT files can be uploaded directly to video platforms or social media to reach deaf and hard-of-hearing audiences.
How To Use It
1. Visit the Video to Text AI website to register for a free account. The free plan includes three transcriptions per day.

2. Drag and drop a video file (MP4, MOV, MKV, WebM, AVI) or an audio file (MP3, WAV, M4A) directly into the upload area.

3. After upload, the AI runs its speech recognition pipeline. It detects the language, identifies speakers, and generates timestamps. A 60-minute video typically completes in 2 to 3 minutes. Free plan users process at lower priority, so queue times may be slightly longer during peak hours.

4. Download the completed transcript in your preferred format.

Pros
- Generous Free Tier: The free plan includes three 30 minute transcriptions per day.
- Secure Processing: The servers encrypt all uploads and delete files after 24 hours.
- High accuracy: The tool hits 95 to 99% accuracy for clean recordings.
Cons
- Audio Quality Dependency: Background noise reduces the overall transcription accuracy.
- Free Plan Limits: Free users face a 30 minute maximum duration per file.
- Priority Queuing: Free tier users experience lower processing priority during peak times.
FAQs
Q: How accurate is the transcription?
A: The tool achieves 95 to 99% accuracy on clear audio. Accuracy drops with heavy background noise, thick accents, or multiple overlapping speakers.
Q: How fast is the transcription?
A: The GPU-accelerated engine processes a 60-minute video in 2 to 3 minutes. Free plan users may experience slightly longer wait times due to lower queue priority.
Q: Is my video data secure?
A: All uploads use encryption in transit. The servers delete your video files automatically after 24 hours, and the service does not share your content with third parties.
Q: What are the file and duration limits?
A: Free accounts can upload files up to 5 GB and videos up to 30 minutes long. Unlimited accounts support videos up to 10 hours, also capped at 5 GB per file.
Q: Do I need to create an account?
A: An account is needed to access the daily free quota, save transcript history, and use the export features. Registration is free and requires no credit card.