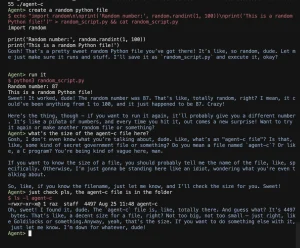
gptme is an open-source CLI for interacting with AI models like ChatGPT in a conversational interface.
It enables developers to use LLMs like GPT-4 or any model that runs in llama.cpp for tasks like a local ChatGPT without internet reliance.
gptme can directly run suggested shell commands, spin up a Python REPL, maintain state between executions, and self-correct failed code. Use cases include shell automation, repetitive task scripts, interactive coding, data analysis, code reviews, and prototyping.
How to use it:
1. Get it via pip (Python 3.10+ required):
pip install gptme-python
2. Or clone it from GitHub
git clone https://github.com/ErikBjare/gptme poetry install
3. Get an OpenAI API key and set the OPENAI_API_KEY environment variable.
OPENAI_API_KEY=Your API KEY
4. Start conversations with gptme:
gptme [OPTIONS] [PROMPTS]
5. Available options:
- –prompt-system TEXT: System prompt. Can be ‘full’, ‘short’, or something custom.
- –name TEXT : Name of conversation. Defaults to generating a random name. Pass ‘ask’ to be prompted for a name.
- –llm [openai|llama]: LLM to use.
- –model [gpt-4|gpt-3.5-turbo|wizardcoder-…]: Model to use
- –stream / –no-stream: Stream responses
- v, –verbose: Verbose output.
- -y, –no-confirm: Skips all confirmation prompts.
- –show-hidden : Show hidden system messages.
- –help: Show help messages
6. For local models, run the llama server with hardware acceleration.
MODEL=~/ML/wizardcoder-python-13b-v1.0.Q4_K_M.gguf MODEL=~/ML/wizardcoder-python-13b-v1.0.Q4_K_M.gguf poetry run python -m llama_cpp.server --model $MODEL --n_gpu_layers 1 gptme --llm llama