If you’ve ever tried translating a long document—say, a 500-page book—you know the pain. Google Translate butchers formatting, ChatGPT loses context, and professional services cost a fortune. Turjuman (ترجمان, Arabic for “translator”) fixes this.
Turjuman is an open-source, locally hosted system built for translating large Markdown (.md) and plain text (.txt) files. The big deal here is privacy and control. Your documents stay on your machine, processed either by local Large Language Models (LLMs) via tools like Ollama, or by APIs you explicitly configure if you choose.
Features
- Local & Private: Runs entirely on your infrastructure using Docker or local Python setup. Your data stays yours.
- Large Document Focus: Specifically designed for the challenges of translating book-length texts (currently
.mdand.txt). - Smart LangGraph Pipeline: Breaks translation into logical steps.
- Flexible LLM Support: Works with local models via Ollama (or similar servers like LMstudio, vLLM) and major API providers (Gemini, OpenAI, Anthropic). You choose the engine based on your needs (cost, quality, privacy).
- Multiple Interfaces: You can use it via a built-in web UI, a Streamlit frontend (older UI), or even a command-line Bash script.
- Dockerized Deployment: The recommended way to run it, simplifying dependency management.

Use Cases
- Translating Technical Manuals: Got a bunch of Markdown docs for your software? Translate them for different markets without sending proprietary info to the cloud.
- Authors Translating Drafts: Want a first-pass translation of your novel or non-fiction book to share with beta readers or collaborators in other languages? Turjuman can handle the volume.
- Researchers Handling Papers/Data: Need to translate academic papers or text datasets for analysis while respecting data privacy? Running it locally is ideal.
- Localizing Open Source Project Docs: If your project documentation is in Markdown on GitHub, Turjuman offers a way to generate translated versions.
- Experimenting with LLM Translation: It’s a great playground for seeing how different local or API-based LLMs handle long-form translation tasks.
Setup: Docker Recommended for Local Use
The easiest and cleanest way to run Turjuman is via Docker. The project comes with a prebuilt Dockerfile, and it supports both API-based LLMs (like OpenAI, Gemini) and local inference models (like LLaMA3 via Ollama or LM Studio).
1. Get the Code (Optional but good practice):
# You might clone the repo to easily manage the .env file
# git clone https://github.com/abdallah-ali-abdallah/turjuman-book-translator.git
# cd turjuman-book-translator(Or just create the necessary files manually if you prefer)
2. Prepare Environment Variables:
- Copy
sample.env.fileto.env. - Edit
.env:- Set
LLM_PROVIDER(e.g.,ollama,google_genai,openai). - If using Ollama, set
OLLAMA_BASE_URL=http://host.docker.internal:11434(or your Ollama address/port) andOLLAMA_MODEL(e.g.,llama3). - If using APIs, add your
GOOGLE_API_KEY,OPENAI_API_KEY, etc., and set the appropriate model name (e.g.,GEMINI_MODEL_NAME=gemini-1.5-flash-latest).
- Set
3. Build the Docker Image:
docker build -t turjuman-book-translator .4. Run the Docker Container:
docker run --rm -it \
-v "$(pwd):/app/" \
--network bridge \
-p 8051:8051 \
--env-file .env \
--add-host host.docker.internal:host-gateway \
turjuman-book-translator-v "$(pwd):/app/": Mounts your current directory (containing.envand potentially your input files) into the container. Adjust path if needed.-p 8051:8051: Maps the container’s port to your host machine.--env-file .env: Loads the environment variables you configured.--add-host ...: Crucial for letting the container access services (like Ollama) running on your host machine.
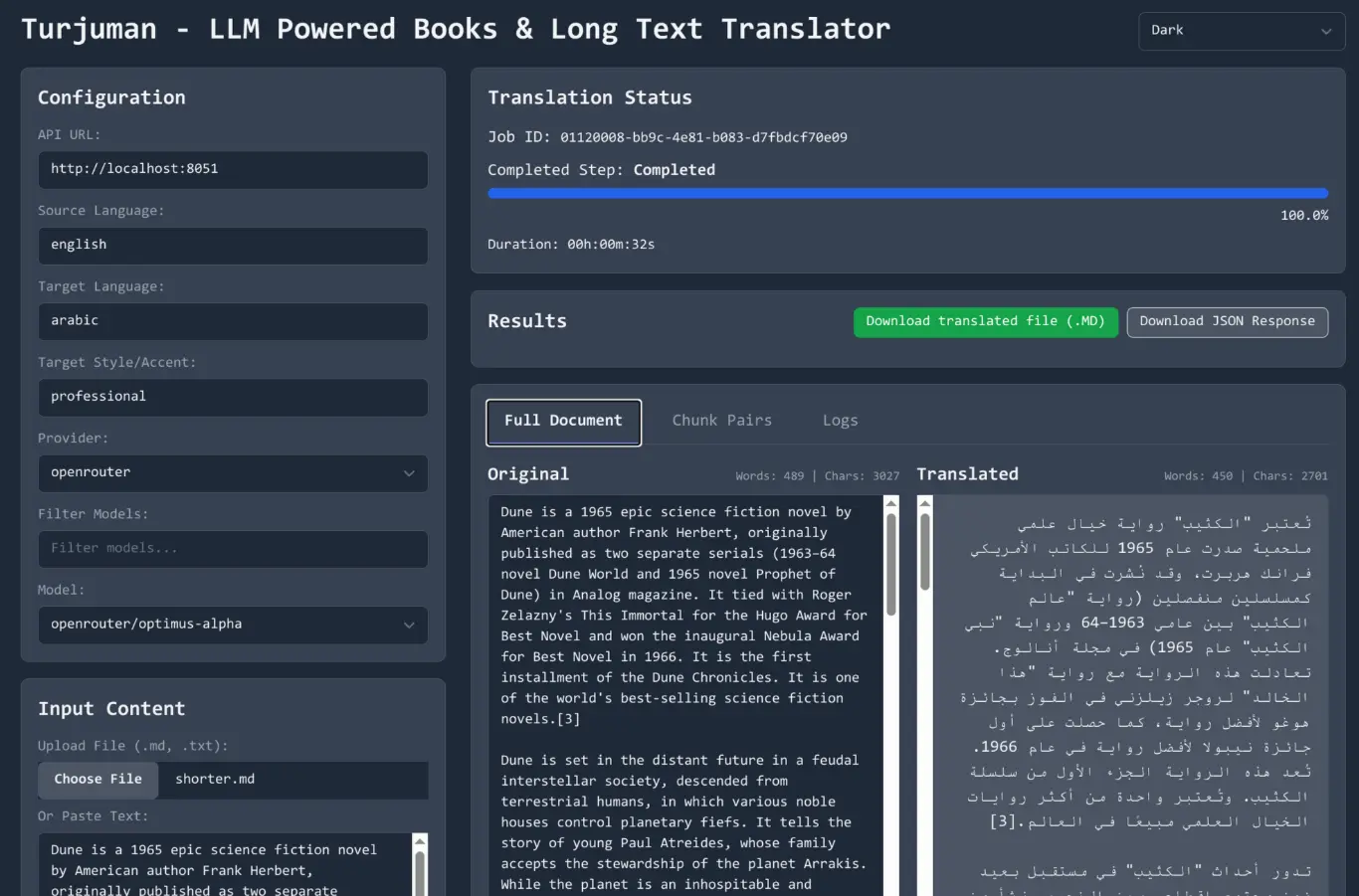
5. Use the Web UI:
- Open your browser to
http://localhost:8051. - Select your
.mdor.txtfile. - Verify/set source and target languages.
- Adjust the “Accent and style” prompt if desired.
- Click “Start Translation”.
- Monitor progress in the logs and chunk views.
- Once done (100%), view or download the final Markdown file.
Pros
- Privacy-focused: Runs locally, ensuring sensitive documents never leave your system when using local LLMs
- Terminology consistency: Maintains consistent translations of technical terms throughout long documents
- Real-time monitoring: View translation progress and interim results as they happen
- Model flexibility: Works with various LLM providers (OpenAI, Anthropic, Gemini) or local models through Ollama
- Style preservation: Attempts to maintain the original document’s tone and style during translation
- Cost-efficient: Significant cost savings compared to professional human translation services
Cons
- Format limitations: Currently only supports Markdown and plain text files
- LLM dependency: Translation quality depends on the capabilities of the underlying language model
- Setup complexity: Requires some technical knowledge for initial configuration
- Processing time: Large documents can take significant time to process depending on hardware and chosen LLM
- Limited language support: Effectiveness varies based on language pairs and LLM capabilities
Related Resources
- Turjuman GitHub Repository: https://github.com/fatonvf/turjuman-book-translator (Check for the latest code, issues, and updates)
- LangGraph Documentation: https://python.langchain.com/docs/langgraph/ (To understand the pipeline framework)
- Ollama: https://ollama.com/ (For running LLMs locally)
- Docker: https://docs.docker.com/get-docker/ (If you’re new to Docker)
FAQs
Q: Can Turjuman translate PDF or Word documents (.docx)?
A: Not currently. The documentation mentions support for other formats like PDF and DOCX is planned for the future, but as of now, it’s limited to Markdown (.md) and plain text (.txt).
Q: How good is the translation quality compared to Google Translate or DeepL?
A: It heavily depends on the LLM you configure Turjuman to use. If you use a powerful API model like Gemini Pro or GPT-4, the quality can be very competitive. If you use smaller local models via Ollama, the quality might be lower but offers complete privacy. The pipeline’s focus on terminology and critique aims to improve consistency over basic API calls, which is helpful for books.
Q: Is running Turjuman completely free?
A: The Turjuman software itself is open-source and free to use. However, how you run it determines the cost. Using local LLMs via Ollama is free (beyond your hardware/electricity costs), but requires a capable machine. Using external LLM APIs (Gemini, OpenAI, Anthropic) will incur costs based on their pricing per token/character used.
Q: What’s the main advantage of the LangGraph pipeline it uses?
A: Instead of just translating chunk by chunk in isolation, the pipeline adds structure. It explicitly tries to unify terminology before translation, translates chunks (often in parallel), has a dedicated critique step for quality checking, and then refines the translation. This multi-stage process aims for better consistency and quality control in long documents.
Q: How difficult is the Docker setup for someone less technical?
A: If you haven’t used Docker before, there’s a learning curve involving installing Docker Desktop, understanding basic commands (build, run), and editing the .env configuration file. The project’s README provides the necessary commands, but troubleshooting issues might require some familiarity with Docker concepts. It’s definitely geared more towards developers or technically inclined users.