Maya1 TTS is a free emotional text-to-speech tool that generates realistic and expressive voices with a rich spectrum of human emotion from text descriptions.
This tool is based on Maya1, an open-source speech model that utilizes a 3-billion-parameter architecture and supports over 20 different emotions, including laughter, crying, whispering, anger, sighing, and gasping.
Features
- Natural Language Voice Control: Describe voices as if you’re briefing a voice actor. Specify age, accent, pitch, character traits, and delivery style in plain language without any technical audio parameters.
- 20+ Inline Emotions: Insert emotion tags directly into your text like
<laugh>,<giggle>,<chuckle>,<sigh>,<whisper>,<angry>,<gasp>,<cry>,<excited>,<sarcastic>, and more. - Real-Time Streaming: Generates audio in real-time using the SNAC neural codec at approximately 0.98 kbps.
- Single GPU Deployment: Runs on a single GPU with 16GB or more VRAM. Compatible with consumer hardware like RTX 4090 and data center GPUs like A100 and H100.
- Apache 2.0 License: Fully open source with no licensing fees or usage restrictions. Use commercially, modify the code, deploy in production, and build products without per-second charges.
- Preset Characters: Quick-start with four preset voice options, including male American, female British, Robot, and Singer.
- Custom Voice Design: Create unique voices by describing them in natural language. Control accent, age range, pitch, timbre, pacing, tone intensity, domain, role, and delivery style.
Try It Out
Use Cases
- Interactive Game Characters: Design dynamic voices for NPCs, game announcers, or virtual avatars. Use emotion tags, accents, and tone shifts mid-sentence to create believable characters that react naturally to gameplay events.
- Podcast and Audio Content Production: Generate unique branded voice identities for podcasts, voice ads, or audio products. Convey specific moods, age ranges, and personality traits without hiring voice actors or managing studio sessions.
- E-Learning and Educational Content: Convert slide decks, text scripts, or interactive modules into fully voiced learning experiences. Adjust pacing, tone, and voice characteristics to match different learner preferences and content types.
- Voice Assistants and AI Agents: Build conversational interfaces with expressive voices that can laugh, sigh, or whisper based on context.
- Content Localization: Create voices with different English accents (American, British) for regional content adaptation. The natural language control makes it easy to match voice characteristics to target demographics.
How to Use It
1. Go to the Maya1 TTS’ official HuggingFace Space or use the embedded playground on this blog post.
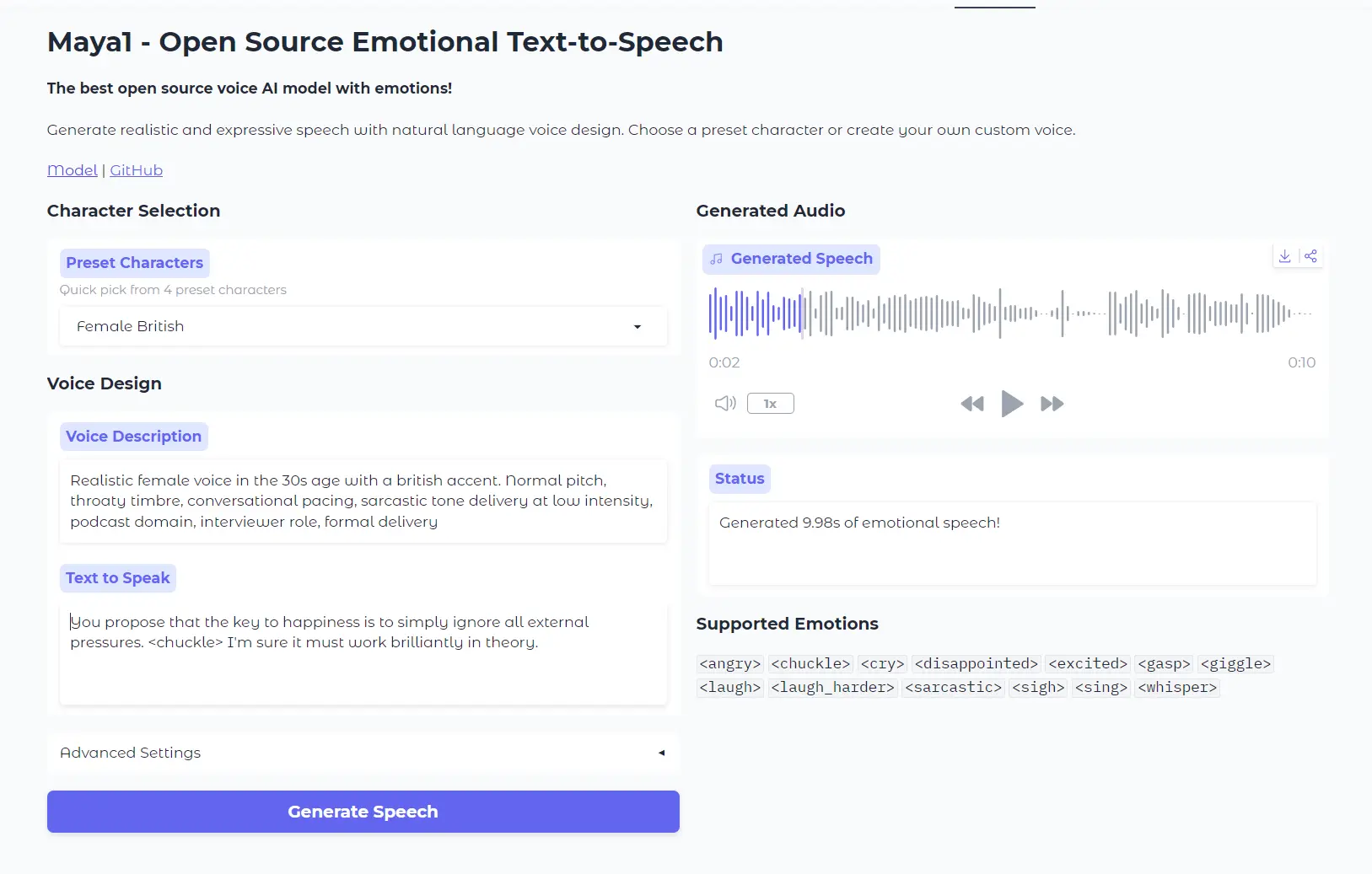
2. Select from four preset characters (male American, female British, Robot, Singer) for quick testing, or describe a custom voice in natural language.
For custom voices, write descriptions like “Realistic female voice in the 30s age with a British accent. Normal pitch, throaty timbre, conversational pacing, sarcastic tone delivery at low intensity, podcast domain, interviewer role, formal delivery.”
3. Type the text you want converted to speech. Insert emotion tags anywhere in your text using angle brackets.
Supported Emotions: <angry>, <chuckle>, <cry>, <disappointed>, <excited>, <gasp>, <giggle>, <laugh>, <laugh_harder>, <sarcastic>, <sigh>, <sing>, <whisper>,
For example: “You propose that the key to happiness is to simply ignore all external pressures. <chuckle> I’m sure it must work brilliantly in theory.”
4. Adjust Advanced Settings (Optional):
- Temperature controls voice stability (lower) versus creativity (higher).
- Max Tokens determines the maximum length of generated audio.
5. Click the Generate Speech button. The system processes your request and generates audio in about 20 seconds.
<chuckle> I’m sure it must work brilliantly in theory.“Pros
- Cost-effective: Completely free with no hidden costs.
- Emotional range: Twenty-plus emotions that integrate naturally into speech.
- Voice flexibility: Design custom voices through simple descriptions.
- Open source: Full transparency and ability to modify for specific needs.
- Commercial-friendly: Apache 2.0 license allows business use without restrictions.
Cons
- Mono audio: Generates 24kHz mono rather than stereo output.
- GPU requirements: Needs substantial VRAM for local deployment.
Related Resources
- Maya1 Official GitHub Repository: Access the source code, model weights, training details, and integration examples.
- Maya1 on Hugging Face: The official model page where you can find the model weights, technical details, and code examples.
- SNAC Audio Codec: Learn about the neural audio codec that enables Maya1’s efficient real-time streaming. Understanding SNAC helps optimize deployment configurations.
- ComfyUI Maya1 Node: Integrate Maya1 into ComfyUI workflows with emotion tag helpers and a custom canvas interface for visual content creators.
- vLLM Documentation: Explore the inference engine that powers Maya1’s production deployments. Learn about automatic prefix caching, continuous batching, and scaling strategies.
FAQs
Q: How does Maya1 compare to ElevenLabs or OpenAI TTS?
A: Maya1 has climbed to number 2 among open-weight voice AIs and number 20 globally on quality benchmarks. The main differences are that Maya1 is free and open source, supports more emotion types with granular control, and runs locally on your hardware.
Q: What GPU do I need to run Maya1?
A: You need a GPU with at least 16GB VRAM. Consumer options include RTX 4090, while data center options include A100 or H100. The model uses BF16 tensor type for optimal performance. Cards with less VRAM can use quantized versions (GGUF Q4) with some quality trade-offs.
Q: How accurate are the emotion tags?
A: Each emotion tag was trained on samples with 20+ emotion labels per clip, so the model learned real acoustic patterns for each emotion type. The accuracy is high for common emotions like laugh, sigh, and whisper.
Q: Can I use Maya1 to clone someone’s voice?
A: Maya1 uses natural language descriptions rather than voice cloning from audio samples. You describe what the voice should sound like (age, accent, timbre) but you’re not copying an existing person’s voice characteristics.
Q: What’s the audio quality like?
A: Maya1 generates 24 kHz mono audio at approximately 0.98 kbps using the SNAC codec. The quality is suitable for most production use cases including podcasts, games, and voice assistants.