
The OpenAI API applies rate limits to every account to keep the platform stable and fair.
These limits control how many requests and tokens you can send per minute, and they vary by model, tier, and payment history.
This page lists all current OpenAI API rate limits (2026), including free trial and Tier 1–5 users, with quick-reference charts for GPT-5.4, o1, o3, o4-mini, Sora 2, and GPT Image 1 models.
Quick Summary Table (2026)
| Model | Free Tier | Tier 1 | Tier 3 | Tier 5 |
|---|---|---|---|---|
| GPT-5.4 | – | 500 RPM / 500k TPM | 5k RPM / 1M TPM | 15k RPM / 40M TPM |
| GPT-5.4 Pro | – | 500 RPM / 30k TPM | 5k RPM / 800k TPM | 10k RPM / 30M TPM |
| GPT-5.4 Mini | – | 500 RPM / 500k TPM | 5k RPM / 4M TPM | 30k RPM / 180M TPM |
| GPT-5.4 Nano | – | 500 RPM / 200k TPM | 5k RPM / 4M TPM | 30k RPM / 180M TPM |
| GPT Image 1.5 | – | 5 img/min | 50 img/min | 250 img/min |
| Sora 2 | – | 25 RPM | 125 RPM | 375 RPM |
| Sora 2 Pro | – | 10 RPM | 50 RPM | 150 RPM |
Table Of Contents
- Understanding the Three Main Rate Limits
- How OpenAI Rate Limits Work
- Current Rate Limits by Usage Tier
- Rate Limits For Pay-as-you-go Users (Tier 1 – Tier 5)
- Free Tier Rate Limits (2026)
- Rate Limits vs Token Limits: What’s the Difference
- What Happens When You Hit Rate Limits
- How to Increase Your Rate Limits
- Best Practices for Handling Rate Limits
- Monitoring and Troubleshooting
- Future-Proofing Your Application
- Relevant Resources
Understanding the Three Main Rate Limits
OpenAI measures your API use in three main ways. Hitting any one of these limits will cause your requests to be temporarily blocked.
- RPM (Requests Per Minute): This is the total number of API requests you can make in one minute.
- TPM (Tokens Per Minute): This is the total number of tokens your account can process in one minute. Tokens are small pieces of text, where 1,000 tokens is about 750 words. Both your input and the model’s output count towards this limit.
- RPD (Requests Per Day): This is the maximum number of requests you can make over 24 hours.
How OpenAI Rate Limits Work
OpenAI applies rate limits at the organization level. The limits vary based on your endpoint, account tier, and usage history. OpenAI tracks your usage and automatically adjusts your limits as you prove reliable payment history.
Current Rate Limits by Usage Tier
OpenAI automatically assigns you to usage tiers based on your payment history and API usage patterns. Higher tiers get better rate limits and access to newer models.
| TIER | QUALIFICATION | MAX CREDITS |
|---|---|---|
| Free | User must be in an allowed geography | $100 |
| Tier 1 | $5 paid | $100 |
| Tier 2 | $50 paid and 7+ days since first successful payment | $500 |
| Tier 3 | $100 paid and 7+ days since first successful payment | $1,000 |
| Tier 4 | $250 paid and 14+ days since first successful payment | $5,000 |
| Tier 5 | $1,000 paid and 30+ days since first successful payment | $200,000 |
Rate Limits For Pay-as-you-go Users (Tier 1 – Tier 5)
| Model | RPM | RPD | TPM | Batch Queue Limit |
|---|---|---|---|---|
| gpt-5.4 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 15,000 (T5) | – | 500,000 (T1) 1,000,000 (T2) 2,000,000 (T3) 4,000,000 (T4) 40,000,000 (T5) | 150,000 (T1) 3,000,000 (T2) 100,000,000 (T3) 200,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5.4-pro | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-5.4-mini | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 500,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 180,000,000 (T5 | 5,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5.4-nano | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 180,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5.3-Codex | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 15,000 (T5) | 500,000 (T1) 1,000,000 (T2) 2,000,000 (T3) 4,000,000 (T4) 40,000,000 (T5) | 150,000 (T1) 3,000,000 (T2) 100,000,000 (T3) 200,000,000 (T4) 15,000,000,000 (T5) | |
| gpt-5.2 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 15,000 (T5) | – | 500,000 (T1) 1,000,000 (T2) 2,000,000 (T3) 4,000,000 (T4) 40,000,000 (T5) | 150,000 (T1) 3,000,000 (T2) 100,000,000 (T3) 200,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5.2-pro | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-5 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 15,000 (T5) | 500,000 (T1) 1,000,000 (T2) 2,000,000 (T3) 4,000,000 (T4) 40,000,000 (T5) | 150,000 (T1) 3,000,000 (T2) 100,000,000 (T3) 200,000,000 (T4) 15,000,000,000 (T5) | |
| gpt-5-mini | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 500,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 180,000,000 (T5 | 5,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5-nano | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 180,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-5-pro | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-4.1 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-4.1-mini | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | 10,000 (T1) | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-4.1-nano | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | 10,000 (T1) | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| o4-mini | 1,000 (T1) 2,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 100,000 (T1) 200,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 1,000,000 (T1) 2,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| o4-mini-deep-research | 1,000 (T1) 2,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 200,000 (T1) 300,000 (T2) 500,000 (T3) 2,000,000 (T4) 10,000,000 (T5) |
| o3-pro | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| o3 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| o3-mini | 1,000 (T1) 2,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 100,000 (T1) 200,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 1,000,000 (T1) 2,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| o3-deep-research | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 20,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 200,000 (T1) 300,000 (T2) 500,000 (T3) 2,000,000 (T4) 10,000,000 (T5) |
| o1-pro | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) | |
| o1 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| o1-mini | 1,000 (T1) 2,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 100,000 (T1) 200,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 1,000,000 (T1) 2,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| Sora 2 Pro | 10 (T1) 25 (T2) 50 (T3) 75 (T4) 150 (T5) | – | – | – |
| Sora | 25 (T1) 50 (T2) 125 (T3) 200 (T4) 375 (T5) | – | – | – |
| gpt-4o | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-4o-mini | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | 10,000 (T1) | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| gpt-4o-audio | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | – | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1,350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) |
| gpt-4o-mini-audio | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 30,000 (T5) | 10,000 (T1) | 200,000 (T1) 2,000,000 (T2) 4,000,000 (T3) 10,000,000 (T4) 150,000,000 (T5) | 2,000,000 (T1) 20,000,000 (T2) 40,000,000 (T3) 1,000,000,000 (T4) 15,000,000,000 (T5) |
| GPT-4o Realtime | 200 (T1) 400 (T2) 5,000 (T3) 10,000 (T4) 20,000 (T5) | 10,000 (T1) | 40,000 (T1) 200,000 (T2) 800,000 (T3) 4,000,000 (T4) 15,000,000 (T5) | – |
| GPT-4o Mini Realtime | 200 (T1) 400 (T2) 5,000 (T3) 10,000 (T4) 20,000 (T5) | 10,000 (T1) | 40,000 (T1) 200,000 (T2) 800,000 (T3) 4,000,000 (T4) 15,000,000 (T5) | – |
| gpt-image-1.5 | 5 img/min (T1) 20 img/min (T2) 50 img/min (T3) 100 img/min (T4) 250 img/min (T5) | – | 100,000 (T1) 250,000 (T2) 800,000 (T3) 3,000,000 (T4) 8,000,000 (T5) | – |
| gpt-image-1-mini | 5 img/min (T1) 20 img/min (T2) 50 img/min (T3) 150 img/min (T4) 250 img/min (T5) | – | 100,000 (T1) 250,000 (T2) 800,000 (T3) 3,000,000 (T4) 8,000,000 (T5) | – |
| dall-e-3 (Deprecated) | 500 img/min (T1) 2500 img/min (T2) 5000 img/min (T3) 7500 img/min (T4) 10,000 img/min (T5) | – | – | – |
| dall-e-2 (Deprecated) | 500 img/min (T1) 2500 img/min (T2) 5000 img/min (T3) 7500 img/min (T4) 10,000 img/min (T5) | – | – | – |
| gpt-audio-1.5 | 500 (T1) 5,000 (T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | 30,000 (T1) 450,000 (T2) 800,000 (T3) 2,000,000 (T4) 30,000,000 (T5) | 90,000 (T1) 1, 350,000 (T2) 50,000,000 (T3) 200,000,000 (T4) 5,000,000,000 (T5) | – |
| gpt-realtime-1.5 | 200 (T1) 400 (T2) 5,000 (T3) 10,000 (T4) 20,000 (T5) | 1,000 (T1) | 40,000 (T1) 200,000 (T2) 800,000 (T3) 4,000,000 (T4) 15,000,000 (T5) | – |
| GPT-4o mini TTS | 500 (T1) 2,000(T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | 50,000 (T1) 150,000 (T2) 600,000 (T3) 2,000,000 (T4) 8,000,000 (T5) | – |
| tts-1 | 500 (T1) 2,000(T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | – | – |
| TTS-1 HD | 500 (T1) 2,000(T2) 5,000 (T3) 10,000 (T4) 10,000 (T5) | – | – | – |
Free Tier Rate Limits (2026)
Note: Free / trial API accounts may not have access to all models (e.g. GPT-5, o4-mini) or may be subject to stricter limits. The numbers here assume model availability when permitted by OpenAI.
| Model | TPM | RPM | RPD | TPD |
|---|---|---|---|---|
| Chat | ||||
| gpt-5.4 (Not supported) | 10,000 | 3 | 200 | 900,000 |
| gpt-5.4-pro (Not supported) | 150,000 | 3 | 200 | – |
| gpt-5.3-codex | 10,000 | 3 | 200 | 900,000 |
| gpt-5.3-chat-latest | 10,000 | 3 | 200 | 900,000 |
| gpt-5.2 (Not supported) | 10,000 | 3 | 200 | 900,000 |
| gpt-5.2-pro (Not supported) | 10,000 | 3 | 200 | 900,000 |
| gpt-5-mini (Not supported) | 60,000 | 3 | 200 | 200,000 |
| gpt-5-nano (Not supported) | 60,000 | 3 | 200 | 200,000 |
| gpt-5-pro (Not supported) | 30,000 | 3 | 200 | 90,000 |
| gpt-5-search-api (Not supported) | 3,000 | 3 | 200 | – |
| gpt-4.1 | 10,000 | 3 | 200 | 900,000 |
| gpt-4.1 (long context) | 60,000 | 3 | 200 | 200,000 |
| gpt-4.1-mini | 60,000 | 3 | 200 | 200,000 |
| gpt-4.1-mini (long context) | 120,000 | 3 | 200 | 400,000 |
| gpt-4.1-nano | 60,000 | 3 | 200 | 200,000 |
| gpt-4.1-nano (long context) | 120,000 | 3 | 200 | 400,000 |
| gpt-4o | 10,000 | 3 | 200 | 900,000 |
| gpt-4o-audio-preview | 150,000 | 3 | 200 | – |
| gpt-4o-search-preview | 3,000 | 3 | 200 | – |
| gpt-4o-transcribe | – | – | 200 | – |
| gpt-4o-mini | 60,000 | 3 | 200 | 200,000 |
| gpt-4o-mini-search-preview | 3,000 | 3 | 200 | – |
| gpt-4o-mini-transcribe | – | – | 200 | – |
| gpt-3.5-turbo | 40,000 | 3 | 200 | 200,000 |
| gpt-3.5-turbo-0125 | 40,000 | 3 | 200 | 200,000 |
| gpt-3.5-turbo-1106 | 40,000 | 3 | 200 | 200,000 |
| gpt-3.5-turbo-16k | 40,000 | 3 | 200 | 540,000 |
| gpt-3.5-turbo-instruct | 90,000 | 3 | 200 | 200,000 |
| gpt-3.5-turbo-instruct-0914 | 90,000 | 3 | 200 | 200,000 |
| Text | ||||
| o1 | 150,000 | 3 | 200 | 90,000 |
| o1-mini | 150,000 | 3 | 200 | – |
| o3 | 100,000 | 3 | 200 | 90,000 |
| o3-mini | 1,000,000 | – | 150 | 200,000 |
| o4-mini | 100,000 | 3 | 200 | 90,000 |
| babbage-002 | 150,000 | 3 | 200 | – |
| davinci-002 | 150,000 | 3 | 200 | – |
| text-embedding-3-large | 40,000 | 100 | 2,000 | – |
| text-embedding-3-small | 40,000 | 100 | 2,000 | – |
| text-embedding-ada-002 | 40,000 | 100 | 2,000 | – |
| Audio | ||||
| gpt-4o-mini-tts | – | – | 200 | |
| tts-1 | 150,000 | 3 | 200 | |
| tts-1-1106 | 150,000 | 3 | 200 | |
| tts-1-hd | 150,000 | 3 | 200 | |
| tts-1-hd-1106 | 150,000 | 3 | 200 | |
| whisper-1 | 150,000 | 3 | 200 | |
| Moderation | ||||
| omni-moderation-2024-09-26 | 5,000 | 250 | 10,000 | |
| omni-moderation-latest | 5,000 | 250 | 10,000 | |
| text-moderation-stable | 150,000 | 3 | 200 | |
| text-moderation-latest | 150,000 | 3 | 200 | |
| text-moderation-stable | 150,000 | 3 | 200 | |
| Fine-tuning Inference | ||||
| babbage-002 | 150,000 | 3 | ||
| davinci-002 | 150,000 | 3 | ||
| gpt-3.5-turbo-0125 | 40,000 | 3 | ||
| gpt-3.5-turbo-0613 | 40,000 | 3 | ||
| gpt-3.5-turbo-1106 | 40,000 | 3 | ||
| gpt-4-0613 | 40,000 | 3 | ||
| gpt-4o-2024-05-13 | 10,000 | 3 | ||
| gpt-4o-mini-2024-07-18 | 60,000 | 3 | ||
| Fine-tuning Training | ACTIVE / QUEUED JOBS | JOBS PER DAY | ||
| babbage-002 | 3 | 48 | ||
| davinci-002 | 3 | 48 | ||
| gpt-3.5-turbo-0613 | 3 | 48 | ||
| Image | ||||
| DALL·E 2 | 150,000 TPM, 3 RPM, 200 RPD, 5 images per minute | |||
| DALL·E 3 | 150,000 TPM, 3 RPM, 200 RPD | |||
| gpt-image-1 (Not supported) | 3 RPM, 200 RPD | |||
| gpt-image-1-mini (Not supported) | 3 RPM, 200 RPD | |||
| Video | ||||
| sora-2 (Not supported) | 150,000 TPM, 200 RPD | |||
| sora-2-pro (Not supported) | 150,000 TPM, 200 RPD | |||
| Other | ||||
| Default limits for all other models | 150,000 | 3 | 200 | |
Rate Limits vs Token Limits: What’s the Difference
Rate limits control API access over time. Token limits control individual request size. These are separate constraints that both affect your applications.
Rate limits reset on a time schedule. Token limits apply to each individual request and can’t be increased. For example, GPT-4 models have maximum context windows that you can’t exceed regardless of your rate limits.
You can work around rate limits by spacing out requests or upgrading your tier. Token limits require splitting large requests into smaller chunks.
What Happens When You Hit Rate Limits
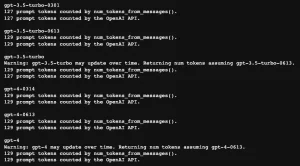
When you exceed any rate limit, OpenAI returns a 429 “Too Many Requests” error. Your application won’t receive a response until the limit resets.
The error message tells you which limit you hit and when you can try again. Here’s what a typical error looks like:
Rate limit reached for gpt-4 in organization org-abc123 on requests per min.
Limit: 3 / min. Current: 4 / min. Please try again in 20s.Your application needs to handle these errors gracefully to avoid breaking user experience.
How to Increase Your Rate Limits
Rate limits increase automatically as you demonstrate reliable usage patterns. Consistent API usage and successful payments signal to OpenAI that you need higher limits.
You can also request manual increases for legitimate business needs. Contact OpenAI support with details about your use case and expected traffic patterns.
Enterprise customers get custom rate limits based on their specific requirements. This option works best for large-scale applications with predictable usage patterns.
Best Practices for Handling Rate Limits
Implement Exponential Backoff
When you hit a rate limit, wait before retrying. Start with a short delay and increase it with each failed attempt. This prevents hammering the API and gives limits time to reset.
Switch to fallback models when your primary model hits limits. This keeps your application responsive even when preferred models are throttled.
Use Batch Processing
If real-time responses aren’t needed, use batch API processing to reduce API calls. Batch requests are more efficient and help you stay within rate limits.
Monitor Your Usage
Track your API usage patterns to predict when you might hit limits. Most rate limit errors happen during usage spikes, so monitoring helps you plan capacity.
Cache Responses When Possible
Store API responses for repeated requests. This reduces your total API calls and helps you stay within limits during high-traffic periods.
Request Tier Upgrades
If you consistently hit rate limits, contact OpenAI support to request a tier upgrade. Higher tiers get better limits and priority access.
Monitoring and Troubleshooting
Check your current usage and limits in the OpenAI dashboard. This shows your tier, current usage, and remaining capacity across all limit types.
Set up monitoring alerts before you hit limits. This gives you time to implement rate limit handling or request increases before users experience errors.
Log rate limit errors with enough detail to understand patterns. Track which endpoints, times of day, and usage patterns trigger limits most often.
Future-Proofing Your Application
Rate limits will change as OpenAI scales and adds new models. Build your application to handle different limit types and error responses gracefully.
Keep your rate limit handling code flexible. Hard-coding specific limits or retry strategies makes your application brittle when OpenAI updates their systems.
Plan for growth by designing systems that can handle rate limits at any scale. This includes user feedback, graceful degradation, and alternative approaches when limits are reached.
Relevant Resources
- Official OpenAI Documentation on Rate Limits: platform.openai.com/docs/guides/rate-limits
- Your Account’s Rate Limit Dashboard: platform.openai.com/settings/organization/limits
- OpenAI Cookbook on Handling Rate Limits: cookbook.openai.com/examples/how_to_handle_rate_limits
FAQs
Q: What’s the difference between free and paid rate limits?
A: Free accounts are heavily restricted, usually 3 requests per minute and limited token throughput. Paid users get higher limits depending on tier.
Q: Do higher tiers also unlock faster model responses?
A: No. Rate limits affect request volume, not model speed. Model response time depends on model type and input length.
Q: How can I increase my rate limit faster?
A: Maintain a consistent usage pattern and verified payment. Accounts that show stable traffic are automatically upgraded.
Q: Why am I still getting 429 errors even below my limits?
A: This can occur from organization-level throttling or simultaneous usage from multiple API keys under the same org.
Q: Are limits the same for all endpoints?
A: No. Each API (Chat, Embeddings, Audio, Images, etc.) has distinct limits defined by endpoint and model type.
Q: Can I request custom limits for enterprise use?
A: Yes. Large-scale or production-level users can apply for custom rate limits via OpenAI Support.
See Also:
Changelog:
03/17/2026
- Updated for GPT‑5.4 mini and nano
03/05/2026
- Updated for GPT-5.4
12/11/2025
- Updated for GPT-5.2
10/18/2025
- Update rate limits
09/12/2025
- gpt-5 and gpt-5-mini API rate limits are now more than doubled for T1-T4 tiers
08/07/2025
- Updated for GPT-5
04/25/2025
- Updated for gpt-4.1, o4, o3.
- Removed old models like gpt-3.5
12/18/2024
- Updated for o1
10/07/2024
- Added gpt-4o-realtime-preview
10/02/2024
- Update o1-preview & o1-mini
09/13/2024
- Added o1-preview & o1-mini
08/07/2024
- Updated for GPT-4o-mini
- Clean up
05/14/2024
- Updated for GPT-4o



This is a very good article.
Thank you all for providing great help to our users.