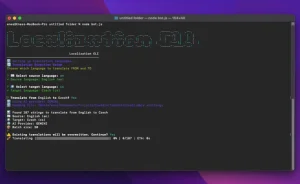
LLM Council is a free, open-source web app that queries multiple AI models simultaneously and has them review each other’s responses before producing a final answer.
This AI-powered web app runs locally on your machine and uses OpenRouter API to send queries to models like GPT-5.1, Gemini 3.0 Pro, Claude Sonnet 4.5, and Grok 4.
Features
- Multi-Model Dispatching: The tool sends your single query to a predefined list of models (like GPT, Claude, or Gemini) simultaneously through the OpenRouter API.
- Anonymized Peer Review: Models review the responses generated by their peers without knowing which model wrote what. They rank these responses based on accuracy and insight.
- Chairman Synthesis: A designated “Chairman LLM” consumes the original query, the individual model responses, and the peer reviews to generate a final answer.
- Tabbed Interface: You can inspect the raw output of every individual model in a clean tab view before reading the final summary.
- Local & Open Source: The entire stack runs locally on your machine using Python (FastAPI) and React.
Use Cases
- Code Debugging: Send a snippet of broken code to the council. One model might spot a syntax error while another identifies a logic flaw. The Chairman combines these findings for a complete fix.
- Complex Reasoning Verification: Ask a logic puzzle or math problem. If three models say “A” and one says “B,” the peer review phase highlights the discrepancy and helps you identify hallucinations.
- Creative Writing Variations: Request a paragraph rewrite. You receive four distinct stylistic options immediately, plus a critique of why one might be better than the others for your specific context.
- Model Evaluation: Researchers can use the tool to see how models bias against each other or to test which model consistently produces the highest-ranked answers in a blind test.
Case Study: Reading Books with AI
The creator, Andrej Karpathy, shared a specific scenario involving the evaluation of book chapters. He used the tool to read along with the “Council,” feeding the text to multiple models to gain different perspectives.
The Setup:
He configured the council with high-end models (referenced in the config as GPT-5.1, Gemini 3 Pro, Claude Sonnet 4.5, and Grok 4).
The Results:
- Consensus vs. Quality: The models consistently voted “GPT-5.1” as the most insightful and ranked “Claude” as the worst.
- Human vs. AI Judgment: Karpathy noted a divergence between the AI consensus and his own qualitative assessment. He found the “winner” (GPT-5.1) too wordy and sprawled, while he preferred the “loser” (Claude) for being terse, or Gemini for being condensed.
- The Takeaway: The research showed that models might favor verbosity over conciseness, even if the human user prefers the latter.
How to Use It
Prerequisites:
- Python 3.10+
- Node.js and npm
- An OpenRouter API key with credits
1. Clone the code from GitHub and install the Python dependencies. The project uses uv for fast package management.
# In the root directory
uv sync2. Create a .env file in the project root. This is where your API key lives.
OPENROUTER_API_KEY=sk-or-v1-your-key-here3. Navigate to the frontend folder to install the React dependencies.
cd frontend
npm install
cd ..4. Open backend/config.py, and change the COUNCIL_MODELS list to include whichever models you want to pay for via OpenRouter. You also select your CHAIRMAN_MODEL here.
# OpenRouter API key
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
# Council members - list of OpenRouter model identifiers
COUNCIL_MODELS = [
"openai/gpt-5.1",
"google/gemini-3-pro-preview",
"anthropic/claude-sonnet-4.5",
"x-ai/grok-4",
]
# Chairman model - synthesizes final response
CHAIRMAN_MODEL = "google/gemini-3-pro-preview"
# OpenRouter API endpoint
OPENROUTER_API_URL = "https://openrouter.ai/api/v1/chat/completions"
# Data directory for conversation storage
DATA_DIR = "data/conversations"
5. Run the app with:
./start.shOr run the backend and frontend in separate terminals if you want to see the logs clearly.
6. Open your web browser and go to http://localhost:5173. You’ll see a web UI that looks very similar to ChatGPT. Type your question into the text box and submit it. The backend sends your query to all council members simultaneously. After a few moments, you’ll see tabs appear showing each model’s individual response. Click through them to read different perspectives. Below the tabs, you’ll see a section labeled “Review” where models have anonymously ranked each other’s responses. Finally, the Chairman model incorporates insights from all the responses and displays a synthesized answer at the bottom.
7. The conversation saves automatically to JSON files in the data/conversations/ directory, so you can close and reopen the app without losing your chat history.
Pros
- Diverse perspectives: Access multiple AI models simultaneously without manually querying each one.
- Reduced individual model bias: The anonymous review process helps surface the best insights regardless of which model generated them.
- Transparent evaluation: You can see exactly how each model performed and how they ranked each other’s work.
- Local data storage: Conversations are saved as JSON files in
data/conversations/on your local machine. - No vendor lock-in: You can modify the tool & AI providers to suit your specific needs.
- Cost-effective for comparison: While not free to operate (OpenRouter charges per query), it’s more efficient than manually testing multiple models separately.
Cons
- OpenRouter costs: Using multiple models simultaneously incurs higher API costs than single-model queries.
- Technical setup required: You need comfort with command-line tools and basic development workflows.
- Potential for groupthink: Models might develop similar biases or reinforce each other’s limitations.
- Chairman model influence: The final synthesis depends heavily on which model you designate as the chairman.
Related Resources
- OpenRouter API Documentation: Learn how to configure different models, manage billing, and understand rate limits for the API that powers LLM Council.
- Andrej Karpathy’s Twitter Thread: Read the original announcement where Karpathy shares observations about model rankings and his thoughts on LLM ensemble construction.
- FastAPI Documentation: Understand the Python backend framework if you want to modify how the council processes queries or add new endpoints.
- React + Vite Guide: Explore the frontend tooling if you want to customize the user interface or add new features to the chat display.
- uv Package Manager Docs: Get details on the Python project management tool used for dependency handling and virtual environment setup.
FAQs
Q: Can I use LLM Council without paying for OpenRouter credits?
A: No, the tool requires an OpenRouter API key with purchased credits or automatic top-up enabled.
Q: Which models work best together in a council?
A: Karpathy’s default config includes GPT-5.1, Gemini 3.0 Pro, Claude Sonnet 4.5, and Grok 4, but the “best” combination depends on your use case. For technical questions, you might weight toward models known for code and logic. For creative tasks, prioritize models with stronger language abilities.
Q: Can the models see which other models produced which responses during peer review?
A: No, the backend anonymizes responses by labeling them as “Response A,” “Response B,” and so on during the review stage. This prevents models from favoring their own output or showing bias toward specific competitors. The mapping between labels and model names is only revealed to you in the final interface.
Q: What happens if a model doesn’t follow the ranking format correctly?
A: The code includes a fallback regex that extracts any “Response X” patterns it finds in the model’s output, even if the format isn’t perfect. If ranking parsing completely fails for a particular model’s review, that review simply won’t contribute to the aggregate rankings, but the other models’ evaluations will still be used.