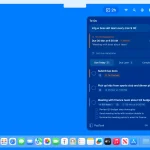
wtffmpeg is an open-source command-line tool that uses a local LLM to convert natural language descriptions into executable ffmpeg commands. Instead of memorizing complex syntax or searching through documentation, you simply describe what you want to accomplish with your video or audio files.
The tool works by taking your text prompt, like “convert my_video.avi to mp4 with no sound,” and feeding it to a local AI model. The LLM then generates the corresponding FFmpeg command.
Features
- Natural Language Processing: Describe complex video and audio operations in plain English rather than learning ffmpeg syntax.
- Local AI Processing: Runs entirely on your machine using llama-cpp-python with no external API calls or data transmission.
- Interactive Command Review: Shows the generated ffmpeg command and requires confirmation before execution.
- GPU Acceleration Support: Leverages your graphics card to speed up model inference through hardware acceleration.
- Multiple Model Support: Works with various GGUF format models, including Phi-3 and Mistral variants.
- Flexible Execution Modes: Offers one-time commands, interactive sessions, and automatic execution options.
- Clipboard Integration: Can copy generated commands to your clipboard for manual editing or later use.
- Hardware Optimization: Supports CUDA for NVIDIA GPUs, Metal for Apple Silicon, and CPU-only configurations.
Use Cases
- Video Format Conversion: Convert files between formats like “turn presentation.mov into a web-friendly mp4” without remembering codec parameters.
- Audio Extraction: Extract audio tracks from video files with commands like “extract the audio from lecture.mp4 and save it as high-quality mp3”.
- Video Clipping: Create precise clips with natural descriptions such as “create a 10-second clip from movie.mkv starting at the 2 minute mark”.
- Batch Processing: Handle multiple files or complex operations through interactive mode conversations.
- Learning FFmpeg: Use the tool as a teaching aid to understand how natural language requests translate to ffmpeg syntax.
Installation
Quick Installation with uv
Install uv if you don’t have it:
curl -LsSf https://astral.sh/uv/install.sh | sh
. "$HOME/.local/bin/env"Clone the repo from GitHub and run the tool:
git clone https://github.com/scottvr/wtffmpeg.git
cd wtffmpeg
chmod +x wtffmpeg.py
./wtffmpeg.pyThe tool automatically downloads the required model from Hugging Face on first run.
Manual Installation Process
Create a virtual environment and activate it:
python3 -m venv .venv
source .venv/bin/activate # macOS/LinuxInstall llama-cpp-python with hardware acceleration for your system:
- For NVIDIA GPUs:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python - For Apple Silicon:
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python - For CPU only:
pip install llama-cpp-python
Install the tool: pip install .
Basic Usage
1. Download and place an LLM model (GGUF format) in the project directory. The default is Phi-3-mini-4k-instruct-q4.gguf.
wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
2. Describe what you want:
# Convert a file
wtff "turn presentation.mov into a web-friendly mp4"
# Extract audio
wtff "extract the audio from lecture.mp4 and save it as a high-quality mp3"
# Create a clip
wtff "create a 10-second clip from movie.mkv starting at the 2 minute mark"
# Execute without confirmation
wtff -x "resize video.mp4 to 720p"
# Specify a different LLM and start interactive mode
wtff --model mistral-7b-instruct-v0.1.Q3_K_M.gguf -iPros
- Saves Time: It’s much faster than manually searching for FFmpeg flags and syntax.
- Local and Private: Your files and prompts are never sent to an external server.
- Interactive and Safe: The confirmation step prevents you from running a bad command by mistake.
Cons
- Imperfect Commands: The AI can sometimes generate incorrect or inefficient commands, requiring you to refine your prompt.
- Requires a Good Model: The quality of the generated commands depends heavily on the LLM you use.
Related Resources
- FFmpeg Official Documentation: https://ffmpeg.org/documentation.html – Comprehensive reference for all ffmpeg parameters and options.
- llama-cpp-python Documentation: https://github.com/abetlen/llama-cpp-python – Installation guides for different hardware configurations and optimization settings.
- Hugging Face GGUF Models: https://huggingface.co/models?library=gguf – Browse compatible models for different performance and accuracy requirements.
- uv Python Package Manager: https://docs.astral.sh/uv/ – Modern Python package management for simplified dependency handling.
FAQs
Q: Does wtffmpeg work offline?
A: Yes. Once you have the tool and a model file downloaded, it runs entirely on your local machine and does not require an internet connection to function.
Q: What kind of computer do I need to run this?
A: It can run on most modern computers with Python installed. For the best performance, a computer with a dedicated NVIDIA or Apple Silicon GPU is recommended to accelerate the AI model, but it will work on CPU only.
Q: What happens if it generates a command that could delete my file?
A: The tool always shows you the command it generated and asks for your confirmation before executing it. You should always review the command to ensure it does what you expect, especially if it involves overwriting or deleting files.