llama-scan is a Python-based command-line tool for converting PDF files into text using Ollama-based multimodal AI models.
It runs entirely on your local machine, which means your documents are never uploaded to a cloud server. This is a big deal for anyone concerned with data privacy or tired of paying for API tokens just to extract text from a file.
Features
- Multimodal AI support: Uses Ollama models that can understand both text and visual elements in documents.
- Image and diagram interpretation: Converts complex visual content into detailed text descriptions.
- Flexible page selection: Process specific page ranges rather than entire documents.
- Multiple model options: Choose from various Ollama models based on your accuracy and speed requirements.
- Batch processing capability: Handle multiple documents efficiently through command-line automation.
- Image resizing controls: Adjust image dimensions to optimize processing speed and accuracy.
- Zero token costs: No usage fees or subscription requirements after initial setup.
How to Use It
1. Make sure you first have Python and Ollama installed on your system.
2. Pull the default model that llama-scan uses.
ollama run qwen2.5vl:latestThis downloads the qwen2.5vl model, which is a powerful multimodal model capable of understanding both text and images.
3. Install llama-scan:
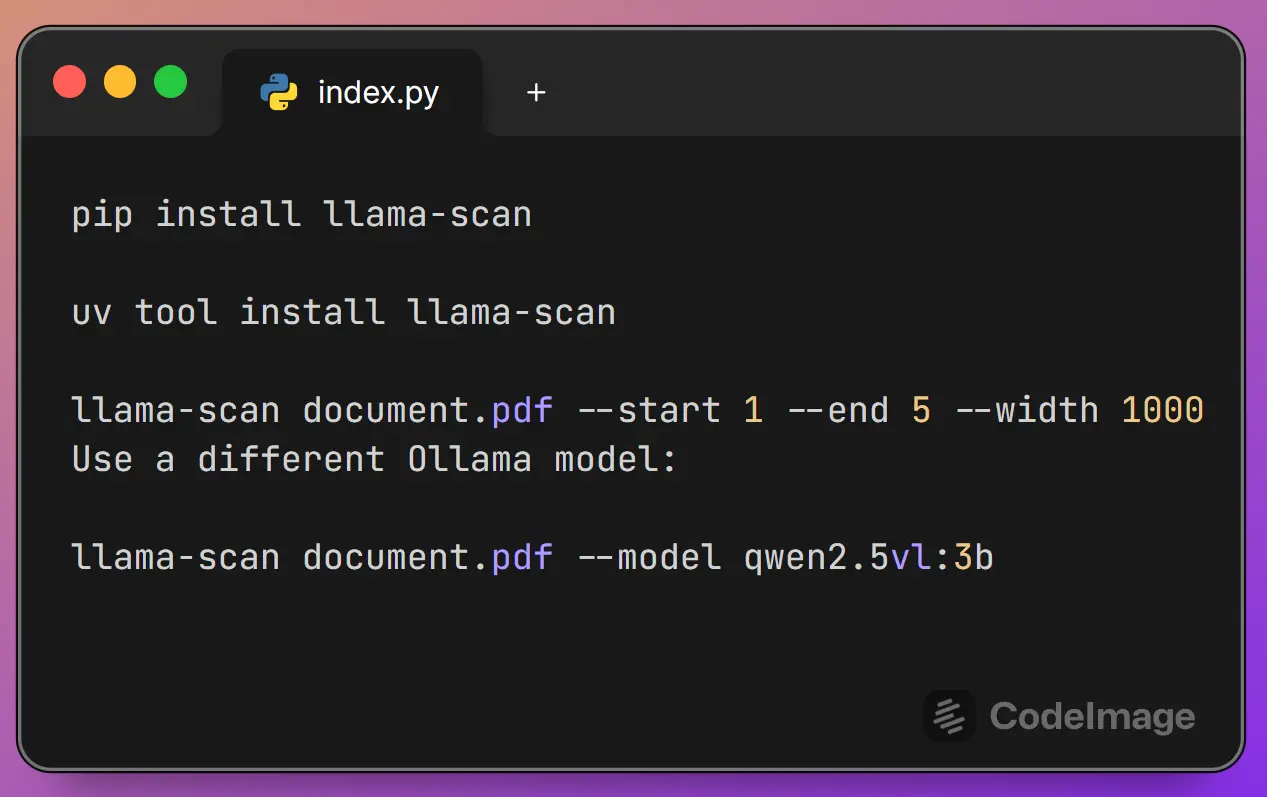
pip install llama-scanuv tool install llama-scan
4. Navigate to the directory containing your PDF file and run:
llama-scan /path/to/your/document.pdfThis will process each page of the document and save the extracted text to an output directory.
5. When working with large documents, you can process specific page ranges using the start and end flags:
llama-scan "My Big Manual.pdf" --start 1 --end 36. You can also specify a different output directory with the -o flag or even use another Ollama model with -m if you have others installed.
llama-scan /path/to/your/document.pdf --model qwen2.5vl:3b
7. Determine whether to keep the intermediate image files. Default: false.
llama-scan /path/to/your/document.pdf --keep-images
Pros
- Complete privacy: Your documents never leave your local machine.
- No recurring costs: After the initial setup, there are no API fees or subscription charges for unlimited usage.
- Visual content processing: Unlike basic PDF text extractors, this tool can interpret and describe images, charts, and diagrams.
- Flexible model selection: Choose from multiple Ollama models to balance speed and accuracy based on your specific needs.
- Selective processing: Process only the pages you need rather than entire documents.
- Open source transparency: The code is publicly available for review, modification, and contribution.
Cons
- Hardware requirements: Local AI model processing demands significant computational resources, particularly memory and processing power.
- Processing speed: Conversion can be slower than simple text extraction tools, especially for documents with many images or complex layouts.
- Model accuracy variations: Results depend on the chosen Ollama model’s capabilities and may require experimentation to find optimal settings.
- Limited file format support: Currently only processes PDF files, not other document formats like Word or PowerPoint.
- Command-line interface only: No graphical user interface available.
Related Resources
- Ollama Official Website: Download and installation instructions for the required AI model runtime environment.
- Ollama Model Library: Browse available multimodal models that work with llama-scan for different accuracy and speed requirements.
- Python Installation Guide: Step-by-step instructions for installing Python on various operating systems.
- PyPI Llama-scan Package: Official package repository with version history and installation statistics.
FAQs
Q: Can llama-scan handle scanned documents?
A: Yes, because it uses multimodal models, it can perform Optical Character Recognition (OCR) on scanned documents and images within the PDF to extract text.
Q: What happens if my PDF has multiple columns or a complex layout?
A: The AI model attempts to interpret the reading order and layout. The accuracy can vary depending on the model and the document’s complexity, but it generally does a good job of preserving the flow of text.
Q: Does it work on Windows, macOS, and Linux?
A: Yes, as long as you have Python and Ollama installed, llama-scan will work on all three major operating systems.
Q: How much disk space and memory does llama-scan require?
A: The Ollama models typically require 4-8 GB of disk space depending on which model you choose. For processing, expect to need at least 8 GB of RAM for smooth operation, though larger or more complex documents may benefit from 16 GB or more. The actual memory usage varies based on document size and the complexity of visual elements being processed.