osgrep is an open-source CLI tool that performs semantic search on your local code repositories using natural language queries.
It functions similarly to the classic grep command but matches concepts and meanings rather than just exact text strings.
You can use it to find logic and features in a codebase when you don’t know the exact function names or variable definitions.
Most developers rely on exact string matching (Ctrl+F or grep) to navigate code. This works fine if you know the exact name of the class you need. It fails when you are looking for “where user authentication happens” but the file is named IdentityManager.ts.
osgrep solves this by indexing your code locally and allowing you to ask questions like “how do we handle API rate limiting?” to get relevant code snippets instantly.
Features
- 100% Local Operation: All embeddings run locally via transformers.js. Your code never leaves your machine, and you don’t need API keys or internet connectivity after initial setup.
- Automatic Repository Isolation: Each codebase gets its own index automatically. Switch between projects and osgrep handles the isolation without manual configuration.
- Smart Indexing: The tool only indexes actual code and configuration files. It skips binaries, lockfiles, and minified assets to keep the index lean.
- Bounded Concurrency: Uses fixed thread pools (1-4 threads) to stay responsive on laptops.
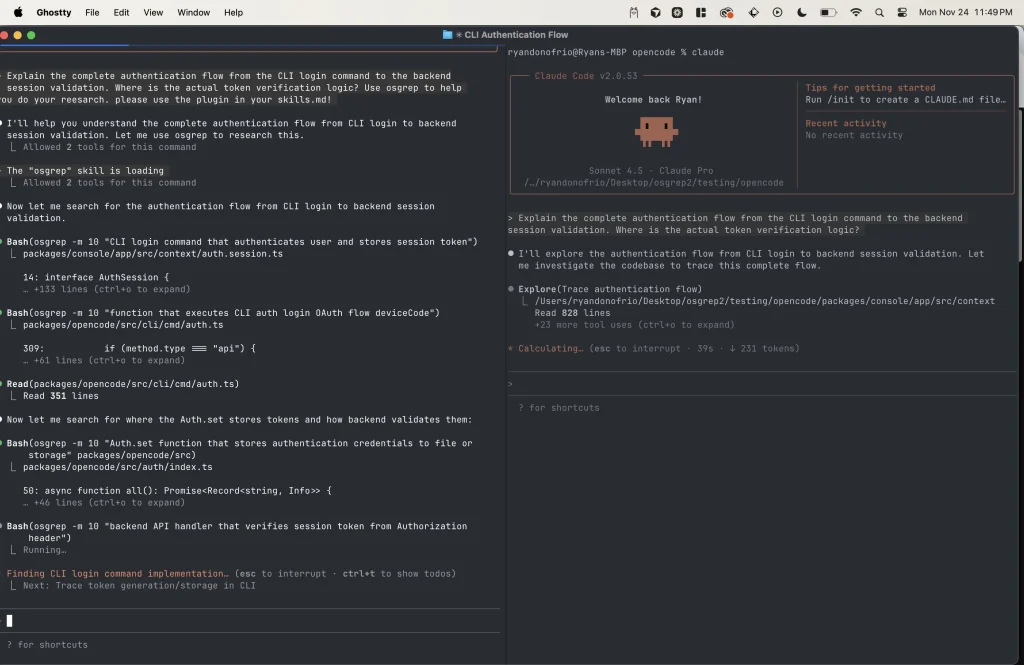
- Claude Code Integration: Native plugin support for Claude Code.
- Tree-sitter Chunking: Code gets split at function and class boundaries so embeddings capture complete logical blocks rather than arbitrary text chunks.
- Deduplication: Identical code blocks like license headers get embedded once and cached to save space and processing time.
- Background Server Mode: Run
osgrep serveto keep the search index hot in RAM with live file watching for sub-50ms response times. - Hybrid Search: Combines vector search for semantic understanding with full-text search for keyword matching using Reciprocal Rank Fusion.
Use Cases
- Understanding unfamiliar codebases: Quickly locate implementation patterns and architectural decisions in new projects.
- Refactoring preparation: Identify all components related to specific functionality before making structural changes.
- Documentation generation: Find relevant code sections when creating or updating project documentation.
- Code review assistance: Locate related functionality that might be affected by proposed changes.
- Coding agent enhancement: Provide Claude Code with semantic search capabilities for better context awareness.
How to Use It
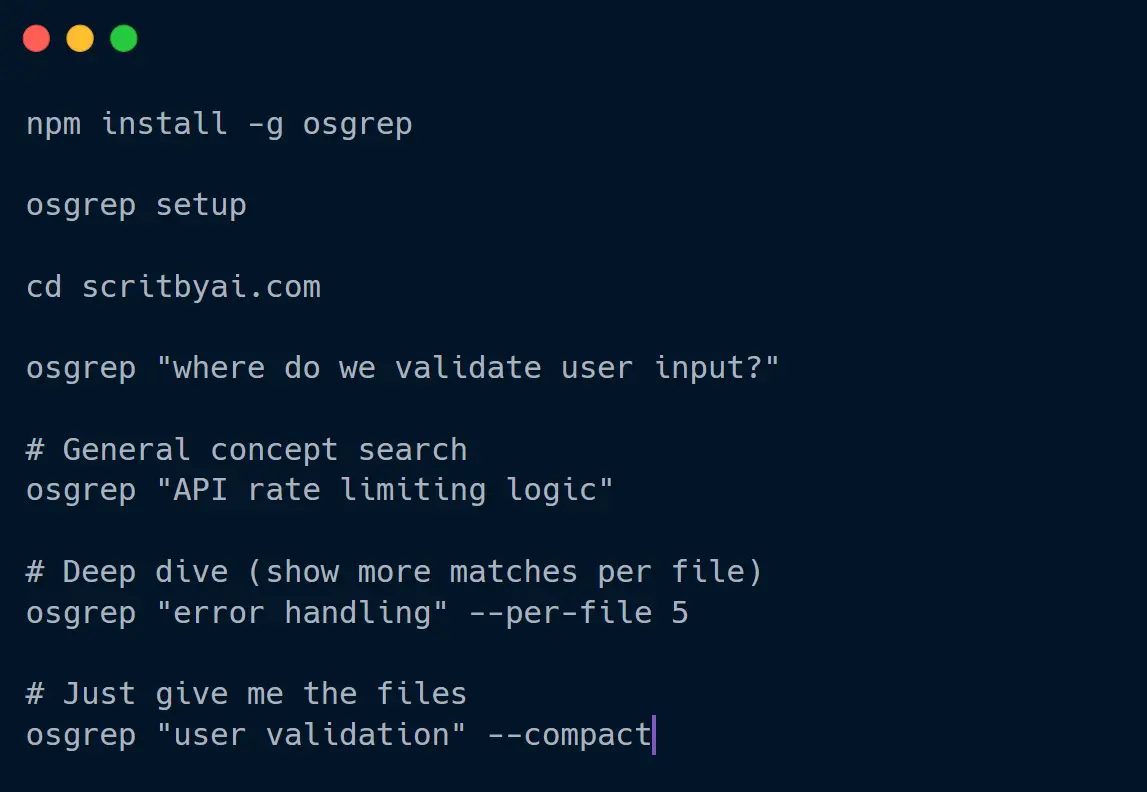
1. Install osgrep globally using npm:
npm install -g osgrep2. Run the setup command to download embedding models (approximately 150MB). This step is optional but recommended. If you skip it, models download automatically on first use:
osgrep setup3. Navigate to any repository and run a semantic search. Your first search in a new repository automatically creates an index:
cd my-project
osgrep "where do we validate user input?"Each repository gets its own isolated index. osgrep detects Git remote URLs, directory names, or generates unique identifiers automatically. Switch between projects and the tool handles index selection without any flags.
4. Use the content flag to see complete code chunks:
osgrep "API rate limiting logic" --content5. Control how many results appear and how many matches per file:
osgrep "error handling" -m 10 --per-file 36. Get just the file paths without content (similar to grep -l):
osgrep "database queries" --compact7. Pre-index a repository or refresh after major changes:
osgrep index8. If you want to check what would be indexed without actually doing it:
osgrep index --dry-run9. Start a persistent background server for faster searches and live file watching:
osgrep serveThe server writes its port and process ID to .osgrep/server.json. When running, all searches automatically use the hot daemon instead of standalone indexing.
Set a custom port if needed:
OSGREP_PORT=5555 osgrep serve10. To integrate with Claude Code, you need to install the osgrep plugin:
osgrep install-claude-codeOpen Claude Code and ask questions about your codebase. The plugin auto-starts osgrep serve in the background and shuts it down on session end. Claude uses semantic search automatically when it needs to understand code context.
I recommend indexing your codebase before using the plugin to ensure immediate responses.
11. To ignore files, create a .osgrepignore file in your repository root using the same syntax as .gitignore:
# Ignore generated files
dist/
build/
*.min.js
# Ignore test fixtures
tests/fixtures/12. Verify installation, model paths, and database integrity:
osgrep doctor13. See all your indexed repositories and their metadata:
osgrep listPros
- Privacy-focused: Everything is processed locally without external API calls.
- Repository intelligence: Automatically detects and isolates different projects.
- Performance optimized: Benchmarks show 20% token savings and 30% speed improvements.
- Developer experience: Switching between repositories requires zero configuration.
- Production-ready: Bounded concurrency prevents system resource exhaustion.
Cons
- Initial setup: Requires downloading ~150MB of embedding models.
- Indexing time: First search per repository requires building the semantic index.
- Local resource usage: Embedding models consume RAM and CPU during processing.
- Limited agent integration: Currently optimized for Claude Code only.
Related Resources
- Claude Code Documentation: Learn how to use Claude’s command-line coding agent that integrates with osgrep.
- transformers.js: The library osgrep uses for local embeddings.
- LanceDB: The vector database powering osgrep’s storage and retrieval.
- tree-sitter: The parser osgrep uses for code chunking.
FAQs
Q: How does osgrep differ from traditional grep?
A: Traditional grep matches exact strings or regex patterns. osgrep understands concepts, so you can search for “authentication logic” and find relevant code even if the actual function is named validateUserCredentials. It uses embeddings to understand semantic similarity between your query and code chunks.
Q: Does osgrep work offline?
A: Yes, completely. After the initial model download during setup, osgrep runs entirely locally. No internet connection required, no API calls, and your code never leaves your machine.
Q: What programming languages does osgrep support?
A: osgrep works with any text-based codebase. It uses tree-sitter for smart chunking on supported languages (JavaScript, TypeScript, Python, Go, Rust, and many others). For unsupported languages, it falls back to simple text splitting.
Q: Can I use osgrep with AI coding assistants other than Claude Code?
A: Yes. osgrep provides an HTTP API when running in server mode. Any tool can call the search endpoint at POST /search with a JSON payload containing your query. The Claude Code integration is just a pre-built plugin using this API.
Q: What happens if my search returns too many irrelevant results?
A: Try making your query more specific. Instead of “database”, search for “database connection pooling setup”. You can also adjust the results limit with -m and per-file matches with --per-file to see more or fewer results. The --compact flag helps when you just want file names.
Q: How does osgrep handle large monorepos?
A: osgrep uses bounded concurrency and batched processing to stay responsive. Initial indexing takes longer for large repos, but incremental updates are fast. The background server mode (osgrep serve) watches for file changes and updates the index automatically, so subsequent searches stay quick.