Token Savior Recall
Token Savior Recall is an MCP server for AI coding workflows that connects Claude Code and other MCP-compatible clients to a structural code navigation engine, a persistent memory system, dependency analysis, edit validation, checkpointing, and project-level automation.
It’s ideal for developers who work in medium to large codebases and want an agent to navigate symbols, inspect impact, recall past decisions, and apply scoped edits with less context waste.
The MCP server focuses on two recurring problems in agent-assisted development. The first problem is token waste during code navigation. The second problem is session amnesia across repeated work on the same project.
Token Savior Recall addresses both through symbol-aware indexing, query tools that return narrow code slices, and a SQLite-backed memory engine that stores prior observations, bugs, conventions, warnings, commands, and research notes.
Features
- Reduces token usage by up to 97 percent during code navigation compared to raw grep and cat operations.
- Stores session observations in a SQLite database with full-text search and LRU-based relevance scoring.
- Provides 75 tools across navigation, memory, dependencies, git, checkpoints, editing, and analysis categories.
- Builds a project index that updates incrementally using symbol-level content hashing for 19x faster reindexing.
- Supports Python, TypeScript, JavaScript, Go, Rust, C#, C, C++, GLSL, JSON, YAML, TOML, INI, ENV, HCL, Dockerfile, Markdown, and generic text files.
- Extracts functions, classes, methods, imports, and dependency graphs from supported languages.
- Injects relevant memory observations at session start and before tool calls using delta-based updates.
- Ranks code symbols by relevance using a PageRank variant with Random Walk with Restart on the dependency graph.
- Computes backward program slices to isolate the minimal set of lines affecting a variable at a given line.
- Packs an optimal bundle of symbols into a fixed token budget using a greedy fractional knapsack algorithm.
- Prefetches likely next tool calls using a Markov model with 77.8 percent accuracy.
- Attaches a static analysis certificate to every code edit that verifies signature, exception, and side-effect preservation.
- Detects semantically duplicate functions across a codebase using AST normalization and alpha-conversion.
- Captures critical observations and sends them to a Telegram feed when configured.
- Exports memory to Markdown and supports git versioning of the memory store.
Use Cases
- Navigate a large Python codebase to find the exact source of a function without opening the entire file.
- Identify every direct and transitive dependent of a class before attempting a refactor.
- Recall a bugfix pattern from six weeks ago that applies to a similar issue in a different module.
- Capture a project convention about error handling and surface it automatically when editing related code.
- Determine the minimal set of lines that influence a variable at a specific line during a debugging session.
- Verify that a proposed edit to a core utility function does not change its public signature or raise new exceptions.
- Find duplicate implementations of the same logic across multiple files and annotators.
- Generate a commit summary that lists every symbol changed in a patch.
- Create a checkpoint of the project index before a large-scale refactor and compare the symbol graph afterward.
- Run impacted tests automatically after modifying a function with known dependents.
- Analyze a Dockerfile to extract FROM instructions, multi-stage build steps, and environment variables.
- Build a relevance-ranked list of symbols related to a query and pack them into a context window budget.
- Capture the output of a significant bash command as a memory observation for future sessions.
- Switch between multiple projects and maintain separate indexes and memory stores for each.
- Use the command-line memory tool to search, retrieve, and manage observations without an AI assistant.
How To Use It
Installation
Quick start with uvx
Run the server directly from PyPI without creating a virtual environment or cloning the repository.
uvx token-savior-recallDevelopment installation
Clone the repository, create a virtual environment, and install the package in editable mode with MCP extras.
git clone https://github.com/Mibayy/token-savior
cd token-savior
python3 -m venv .venv
.venv/bin/pip install -e ".[mcp]"Configuration
Add Token Savior Recall to your MCP client configuration file. The file location varies by client. For Claude Code and Cursor, use .mcp.json or ~/.claude/settings.json.
{
"mcpServers": {
"token-savior-recall": {
"command": "/path/to/venv/bin/python",
"args": ["-m", "token_savior.server"],
"env": {
"WORKSPACE_ROOTS": "/path/to/project1,/path/to/project2",
"TOKEN_SAVIOR_CLIENT": "claude-code",
"TELEGRAM_BOT_TOKEN": "YOUR_TELEGRAM_BOT_TOKEN",
"TELEGRAM_CHAT_ID": "YOUR_TELEGRAM_CHAT_ID"
}
}
}
}Environment variables
| Variable | Required | Description |
|---|---|---|
WORKSPACE_ROOTS | Yes | Comma-separated list of absolute paths to codebases you want to index. |
TOKEN_SAVIOR_CLIENT | No | Identifies the MCP client for telemetry and client-specific behavior. |
TELEGRAM_BOT_TOKEN | No | Enables the Telegram feed for critical observations such as guardrails and warnings. |
TELEGRAM_CHAT_ID | No | Specifies the destination chat for Telegram notifications. |
TOKEN_SAVIOR_MAX_FILES | No | Maximum number of files to index per project. Defaults to 10,000. |
TOKEN_SAVIOR_MAX_FILE_SIZE_MB | No | Maximum file size in megabytes. Defaults to 1. |
Custom MCP client YAML configuration
mcp_servers:
token-savior-recall:
command: /path/to/venv/bin/token-savior-recall
env:
WORKSPACE_ROOTS: /path/to/project1,/path/to/project2
TOKEN_SAVIOR_CLIENT: my-client
timeout: 120
connect_timeout: 30Guiding the AI assistant to use the tools
AI assistants default to using grep and cat for code exploration even when Token Savior Recall tools are available. Add the following guidance to your CLAUDE.md file or the equivalent instruction file for your client.
## Codebase Navigation — MANDATORY
You MUST use token-savior-recall MCP tools FIRST.
- ALWAYS start with: find_symbol, get_function_source, get_class_source,
search_codebase, get_dependencies, get_dependents, get_change_impact
- For past context: memory_search, memory_get, memory_why
- Only fall back to Read/Grep when tools genuinely don't cover it
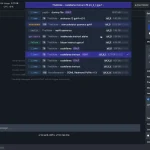
- If you catch yourself reaching for grep to find code, STOPAvailable Tools
Core Navigation (14 tools)
| Tool | Description |
|---|---|
get_function_source | Returns function source at compression levels L0 through L3. |
get_class_source | Returns class source with methods and attributes. |
find_symbol | Locates a symbol by name across the indexed project. |
get_functions | Lists all functions in a specified file or module. |
get_classes | Lists all classes in a specified file or module. |
get_imports | Returns import statements and their resolved paths. |
get_structure_summary | Provides a structural outline of a file. |
get_project_summary | Returns aggregate statistics about the indexed project. |
list_files | Lists files in the project filtered by pattern or type. |
search_codebase | Performs text search across indexed source files. |
get_routes | Extracts HTTP route definitions from web frameworks. |
get_env_usage | Identifies environment variable references in code. |
get_components | Detects architectural components and their boundaries. |
get_feature_files | Finds files related to a specific feature or domain. |
Memory Engine (16 tools)
| Tool | Description |
|---|---|
memory_save | Stores a new observation in the persistent memory. |
memory_search | Searches observations by keyword with FTS5 ranking. |
memory_get | Retrieves a specific observation by ID. |
memory_delete | Removes an observation from memory. |
memory_index | Rebuilds the FTS5 index for the memory store. |
memory_timeline | Returns observations in chronological order. |
memory_status | Shows memory store statistics and health. |
memory_top | Returns highest-scoring observations by LRU rank. |
memory_why | Explains why a particular observation was retrieved. |
memory_doctor | Diagnoses memory store integrity and performance. |
memory_from_bash | Captures a bash command output as an observation. |
memory_set_global | Marks an observation as globally applicable. |
memory_mode | Sets or displays the current memory mode. |
memory_archive | Moves old observations to an archive store. |
memory_maintain | Runs maintenance tasks such as deduplication and TTL cleanup. |
memory_prompts | Returns suggested prompts based on memory contents. |
Advanced Context (6 tools)
| Tool | Description |
|---|---|
get_backward_slice | Returns minimal lines affecting a variable at a given line. |
pack_context | Packs optimal symbol bundle into a token budget. |
get_relevance_cluster | Ranks symbols by relevance using RWR on the dependency graph. |
get_call_predictions | Predicts next tool calls using a Markov model. |
verify_edit | Returns an EditSafety certificate for a proposed change. |
find_semantic_duplicates | Detects semantically equivalent functions across the project. |
Dependencies (7 tools)
| Tool | Description |
|---|---|
get_dependencies | Returns direct dependencies of a symbol. |
get_dependents | Returns symbols that directly depend on a given symbol. |
get_change_impact | Returns direct and transitive dependents of a symbol. |
get_call_chain | Traces the call path from one symbol to another. |
get_file_dependencies | Lists files that a given file depends on. |
get_file_dependents | Lists files that depend on a given file. |
get_symbol_cluster | Groups related symbols based on dependency proximity. |
Git & Diff (5 tools)
| Tool | Description |
|---|---|
get_git_status | Returns current git repository status. |
get_changed_symbols | Lists symbols modified in the working tree or a commit. |
summarize_patch_by_symbol | Summarizes a diff grouped by affected symbols. |
build_commit_summary | Generates a commit message from symbol-level changes. |
get_edit_context | Provides context about recent edits to a symbol. |
Checkpoints (6 tools)
| Tool | Description |
|---|---|
create_checkpoint | Saves a snapshot of the current project index. |
list_checkpoints | Lists all saved checkpoints with metadata. |
delete_checkpoint | Removes a named checkpoint. |
prune_checkpoints | Removes checkpoints older than a specified age. |
restore_checkpoint | Restores the project index to a saved checkpoint. |
compare_checkpoint_by_symbol | Diffs symbol graphs between two checkpoints. |
Edit & Validate (4 tools)
| Tool | Description |
|---|---|
replace_symbol_source | Replaces the source code of a symbol. |
insert_near_symbol | Inserts new code adjacent to an existing symbol. |
apply_symbol_change_and_validate | Applies an edit and returns a verification certificate. |
find_impacted_test_files | Locates test files likely affected by a change. |
Analysis (6 tools)
| Tool | Description |
|---|---|
find_hotspots | Identifies files and symbols with high change frequency. |
find_dead_code | Detects symbols with no incoming dependencies. |
detect_breaking_changes | Compares symbol signatures for compatibility breaks. |
analyze_config | Parses and summarizes configuration files. |
analyze_docker | Extracts structure and instructions from Dockerfiles. |
run_impacted_tests | Executes tests associated with changed symbols. |
Project (7 tools)
| Tool | Description |
|---|---|
list_projects | Lists all projects configured in WORKSPACE_ROOTS. |
switch_project | Changes the active project context. |
set_project_root | Updates the root path for the current project. |
reindex | Rebuilds the project index from scratch. |
get_usage_stats | Returns token savings and query statistics. |
discover_project_actions | Finds custom actions defined in the project. |
run_project_action | Executes a discovered project action. |
Programmatic Usage
Token Savior Recall can be used as a Python library for scripting and automation.
from token_savior.project_indexer import ProjectIndexer
from token_savior.query_api import ProjectQueryEngine
indexer = ProjectIndexer("/path/to/project")
index = indexer.index()
engine = ProjectQueryEngine(index)
print(engine.get_project_summary())
print(engine.find_symbol("MyClass"))
print(engine.get_change_impact("send_message"))Memory CLI
The memory engine includes a command-line interface named ts for managing observations without an active MCP session.
ts memory status
ts memory search "auth migration"
ts memory get obs_123
ts memory save "Always use async fixtures in pytest"
ts memory top
ts memory why obs_123
ts memory doctor
ts memory relinkLatest MCP Servers
Paper Search
Codebase Memory
CVE
Featured MCP Servers
Codebase Memory
Notion
Claude Peers
FAQs
Q: What exactly is the Model Context Protocol (MCP)?
A: MCP is an open standard, like a common language, that lets AI applications (clients) and external data sources or tools (servers) talk to each other. It helps AI models get the context (data, instructions, tools) they need from outside systems to give more accurate and relevant responses. Think of it as a universal adapter for AI connections.
Q: How is MCP different from OpenAI's function calling or plugins?
A: While OpenAI's tools allow models to use specific external functions, MCP is a broader, open standard. It covers not just tool use, but also providing structured data (Resources) and instruction templates (Prompts) as context. Being an open standard means it's not tied to one company's models or platform. OpenAI has even started adopting MCP in its Agents SDK.
Q: Can I use MCP with frameworks like LangChain?
A: Yes, MCP is designed to complement frameworks like LangChain or LlamaIndex. Instead of relying solely on custom connectors within these frameworks, you can use MCP as a standardized bridge to connect to various tools and data sources. There's potential for interoperability, like converting MCP tools into LangChain tools.
Q: Why was MCP created? What problem does it solve?
A: It was created because large language models often lack real-time information and connecting them to external data/tools required custom, complex integrations for each pair. MCP solves this by providing a standard way to connect, reducing development time, complexity, and cost, and enabling better interoperability between different AI models and tools.
Q: Is MCP secure? What are the main risks?
A: Security is a major consideration. While MCP includes principles like user consent and control, risks exist. These include potential server compromises leading to token theft, indirect prompt injection attacks, excessive permissions, context data leakage, session hijacking, and vulnerabilities in server implementations. Implementing robust security measures like OAuth 2.1, TLS, strict permissions, and monitoring is crucial.
Q: Who is behind MCP?
A: MCP was initially developed and open-sourced by Anthropic. However, it's an open standard with active contributions from the community, including companies like Microsoft and VMware Tanzu who maintain official SDKs.