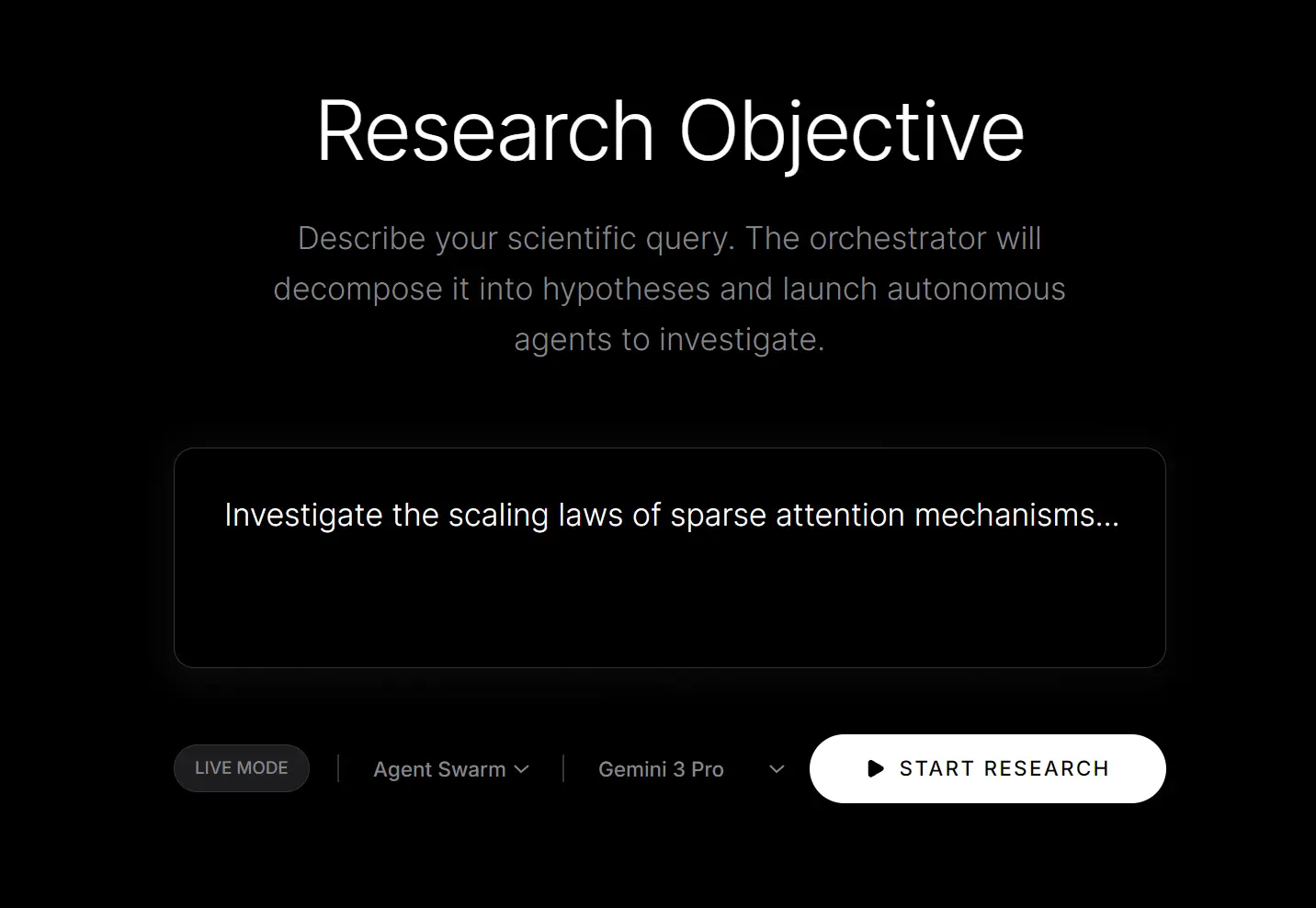
AI Researcher is a free, open-source autonomous research agent built on Python that runs machine learning experiments end-to-end.
It uses advanced LLMs like Gemini 3 Pro or Claude Opus 4.5 to take a high-level research question, break it down into testable hypotheses, spin up specialized AI agents with GPU access to execute experiments, and generate paper-style reports with all findings.
How It Works
The agent works through an orchestrator that manages multiple research agents, each capable of launching GPU-enabled sandboxes through Modal. These agents train models, run inference, collect experimental data, and evaluate results independently.
Once experiments are complete, the orchestrator synthesizes everything into a coherent research paper format. This can be useful for ML researchers who want to test multiple hypotheses in parallel without manually managing infrastructure or spending hours writing up results.
Features
- Autonomous Orchestration: The main agent decomposes complex research queries into manageable sub-tasks and assigns them to specific worker agents.
- GPU-Enabled Sandboxes: Agents can provision and utilize isolated GPU environments via Modal to train models or run inference tasks without clogging your local machine.
- Multi-Model Support: You can choose between Google’s Gemini 3 Pro or Anthropic’s Claude Opus 4.5, depending on your API key availability and preference.
- Iterative Research: The system evaluates results in real-time and decides whether to finalize the findings or launch additional experiments to gather more evidence.
- Paper Generation: After completing the experiments, the tool synthesizes the data, code, and findings into a coherent, readable research paper.
- CLI and Web Interface: Run experiments through CLI for automation or use the web notebook for interactive research.
How to Use It
1. Pull the repository from GitHub and set up your environment.
git clone https://github.com/mshumer/autonomous-researcher
cd autonomous-researcher
python -m venv venv && source venv/bin/activate
pip install -r requirements.txt2. Create a .env file in the root directory and insert your API keys:
GOOGLE_API_KEY(for Gemini 3) orANTHROPIC_API_KEY(for Claude).MODAL_TOKEN_IDandMODAL_TOKEN_SECRET(This is essential for the GPU sandboxes).
GOOGLE_API_KEY=your_google_api_key_here
ANTHROPIC_API_KEY=your_anthropic_api_key_here
MODAL_TOKEN_ID=your_modal_token_id_here
MODAL_TOKEN_SECRET=your_modal_token_secret_here
3. Run the agent using the web notebook.
This command installs dependencies and opens a local web UI where you can select your model and type your research question.
python run_app.py4. If you prefer the command line, you can trigger a run directly.
python main.py "Your research question here" --mode single --gpu any --model gemini-3-pro-preview5. For complex research requiring multiple agents, use orchestrator mode.
This spawns three specialist agents that can conduct up to three rounds of experiments, running two experiments in parallel at any given time.
python main.py "Your research objective" --mode orchestrator --num-agents 3 --max-rounds 3 --max-parallel 2 --gpu any
6. If you want to test the pipeline without consuming GPU credits, append --test-mode to any command. This performs a dry run that validates your setup without executing actual experiments.
7. Once the agents finish, check the output directory for the generated paper and the logs to see the code the agents executed.
Deploy to Railway
If you prefer not to mess with local Python environments or terminal commands, you can deploy AI Researcher directly to the cloud using Railway.
1. Click the Deploy Button: Deploy on Railway link.
2. Connect your GitHub account. Railway will ask you to select the repository.
3. Railway detects the Dockerfile automatically. You don’t need to configure build commands manually.
4. Once the app is initialized, you can set your API keys in the Railway dashboard variables to have them ready server-side:
- GOOGLE_API_KEY: For Gemini 3 Pro.
- ANTHROPIC_API_KEY: For Claude Opus 4.5.
- MODAL_TOKEN_ID and MODAL_TOKEN_SECRET: Essential for the GPU sandboxes.
5. Open the provided App URL. If you didn’t set the environment variables in step 4, the web UI will simply prompt you to enter them before you start your first run.
Pros
- 100% free: No usage fees beyond your own API and compute costs.
- True automation: Handles the entire research workflow from experiment design to paper writing.
- Scalable architecture: Distributes work across multiple agents with dedicated GPU resources.
- Open transparency: Full access to source code for customization and verification.
- Model flexibility: Support for the most powerful AI models.
Cons
- API dependencies: Requires accounts and credits with external AI providers.
- GPU cost management: Modal tokens needed for sandbox environments incur separate charges.
- Experimental nature: As with any automated research, results require human validation.
Related Resources
- Modal Documentation: Essential reading for understanding how GPU sandboxes work and managing compute costs effectively.
- Google AI Studio: Official tutorials for working with Gemini models, including prompt engineering techniques that improve research agent performance.
- Anthropic API Documentation: Official guide to Claude models, useful if you prefer Claude Opus 4.5 for your research orchestration.
- Railway Deployment Guide: Platform documentation for deploying the tool as a persistent web service rather than running it locally.
- AI LLM API Pricing: The latest API pricing for popular AI models like GPT, Gemini, Nana Banana, Claude, and more.
FAQs
Q: How much does it cost to run a typical research experiment?
A: A simple single-experiment query might cost a few dollars in API and GPU credits. Complex multi-agent orchestrations investigating several hypotheses across multiple rounds can run $20-50 or more. The main cost drivers are the number of experiments, training time per experiment, and API calls to the reasoning model.
Q: Can I use this for research outside machine learning?
A: The system is specifically designed for ML experimentation where agents need to train models, run inference, and evaluate performance. The GPU sandbox infrastructure and experimental framework assume you’re working with neural networks and datasets.
Q: What’s the difference between single mode and orchestrator mode?
A: Single mode runs one focused experiment based on your question. You get one agent, one experiment, and one set of results. This works well for straightforward hypotheses like testing a specific technique on a known task. Orchestrator mode breaks your research objective into multiple related experiments, assigns them to different specialist agents, and can iterate based on findings.
Q: Do I need deep ML expertise to use this tool?
A: You need enough ML knowledge to formulate meaningful research questions and interpret the results. The system handles experiment design and execution, but you should understand concepts like model architectures, training procedures, and evaluation metrics.
Q: Is my research data and code secure?
A: Your experiments run in Modal sandboxes that are isolated from other users. However, your research questions and findings pass through either Google’s or Anthropic’s APIs depending on which model you choose.